




































































Are You Struggling to Decide Between Fine-Tuning and Training Your AI Model From Scratch?
In the rapidly evolving landscape of artificial intelligence, the decision between fine-tuning a pre-trained model or training from scratch can determine the success or failure of your AI initiative. Fine-tuning is a machine learning technique that adapts a pre-trained model to perform better on specific tasks by retraining its weights on new data, requiring significantly less computational resources than building a model from scratch. Training from scratch involves building and training a new model with randomly initialized weights using your complete dataset, offering complete control over architecture but demanding substantial computational power and time.
Here's the deal:
Your choice impacts everything—from project timelines to budget allocations, from model performance to scalability. And in 2026, with AI models becoming increasingly sophisticated, this decision carries more weight than ever before.

What is Fine-Tuning in Machine Learning?
Fine-tuning is a process in deep learning where a model initially designed for one task is specialized to perform a new, related task through additional training. Think of it as giving an already educated professional advanced training in a specialized field—you're not starting from kindergarten; you're building on existing expertise.
Fine-tuning uses smaller, specific datasets to refine pre-trained AI model capabilities and improve their performance in a particular domain. Instead of teaching a model everything from scratch, you leverage the vast knowledge it has already acquired from training on massive datasets and simply adjust it to excel at your specific use case.
The Fine-Tuning Process: A Technical Breakdown
Here's how fine-tuning actually works:
Step 1: Model Selection
You start with a foundation model—something like GPT-4, BERT, or LLaMA—that has been trained on billions of parameters. According to the Stanford 2024 AI Index, the number of new foundation models is doubling year over year, giving you an ever-expanding selection of pre-trained models to choose from.
Step 2: Layer Configuration
When fine-tuning, it's common to adjust the deeper layers of the model while keeping the initial layers fixed, as initial layers capture generic features like edges or textures, while deeper layers capture more task-specific patterns.
Step 3: Dataset Preparation
You prepare your domain-specific dataset. The beauty of fine-tuning? You don't need millions of examples. A medical research paper summarization model was successfully fine-tuned using just 15,000 abstracts, generating summaries that saved researchers hours of work within a few days.
Step 4: Retraining
The model's parameters are adjusted using your specific data, typically with a lower learning rate to preserve the foundational knowledge while adapting to your use case.
What is Training From Scratch?
Training from scratch means exactly what it sounds like—building your AI model from the ground up with no pre-existing knowledge. It involves building and training a new model on the fly using your dataset, starting with random initial weights and continuing through the entire training process.
This approach is like raising a child from birth versus hiring an experienced professional—both have their place, but the investment required is dramatically different.
When Training From Scratch Makes Sense
Despite the resource intensity, training from scratch isn't just for tech giants. Consider these scenarios:
Unique Data Requirements
When your dataset is unique and vastly different from any present dataset, or when designing new model architectures or trying out new methods, training from scratch becomes necessary.
Novel Architectures
If you're pushing the boundaries of AI research or developing entirely new approaches, you'll need the flexibility that only training from scratch provides.
Industry-Specific Applications
When working on a model for a rare, underrepresented language where pre-trained models lack even basic vocabulary support, training from scratch becomes the only viable option.
The Cost Factor: Breaking Down the Numbers
Let's talk money—because in matter significantly.

Here's what the numbers reveal:
Training From Scratch: The Price Tag
Training an LLM from scratch has significant cost: Google's Gemini Ultra reportedly cost $191 million to train, while OpenAI's GPT-4 cost an estimated $78 million. Even smaller models aren't cheap—Databricks' DBRX cost $10 million to train from scratch.
But wait—there's more nuance here:
Costs for building a large-scale model like a large language model start around $2-4 million, with millions in recurring costs to run them.
Fine-Tuning: The Cost-Effective Alternative
Fine-tuning dramatically reduces these numbers. While training an LLM from scratch would require around 8,100 GPUs for ten days costing thousands of dollars, fine-tuning can be accomplished for approximately $10 in cloud costs.
Real-World Cost Comparison:
- Training GPT-4 scale model: $78-191 million
- Fine-tuning a 7B parameter model: $10-100 depending on approach
- Training a 70B model from scratch: $500,000 - $1,000,000 for 1 trillion tokens
- Fine-tuning with parameter-efficient methods: Less than $1,000 in most cases
Fine-tuning involves significant upfront costs for training large models with GPUs or TPUs, but for fixed domains where repeated tasks are common, it can be more cost-effective in the long run.
"Fine-tuning has revolutionized our approach to AI model adaptation. This targeted approach allows for efficient model adaptation, producing impressive results without the need for extensive training data." — Simon Brisk, Founder & SEO Strategist at Click Intelligence
GPU Requirements: The Hardware Reality Check
Understanding GPU requirements is crucial for planning your AI project. Let's break down what you actually need:
For Training From Scratch
Small Models (7B parameters): Training a 7B parameter model requires a minimum of 4 GPUs with 16GB VRAM each, though ideally 2-4 A100 GPUs (40GB each) for faster training, and takes approximately 1 month on 8 A100 GPUs (40GB each) for 1 trillion tokens.
Large Models (70B parameters): Training a 70B parameter model requires a minimum of 16 GPUs with 40GB VRAM each, ideally 32 A100 GPUs (40GB each) for efficient training, taking 2-3 months on 16 A100 GPUs or 1 month on 32 A100 GPUs for 1 trillion tokens.
For Fine-Tuning
The requirements drop dramatically:
The absolute minimum for fine-tuning is around 12-16 GB VRAM when using QLoRA or other quantization methods—for example, a 7B model can be fine-tuned on a single RTX 3060 (12 GB), though training will be slower and batch sizes limited.
Practical Setup for Most Teams: For smoother performance, 24 GB VRAM is considered a realistic minimum for most parameter-efficient fine-tuning setups.
For training, the LLaMA 7B variant requires at least 24GB of VRAM, while the 65B variant necessitates a multi-GPU configuration with each GPU having 160GB VRAM or more, such as 2x-4x NVIDIA A100 or H100.
Time Investment: Speed to Market Matters
In AI development, time isn't just money—it's competitive advantage.
Training From Scratch Timelines
Training models from scratch can take several months, if not years, before the model performs to the expected standard. Even smaller projects face substantial time requirements:
- 7B Model: 1-2 months on appropriate GPU clusters
- 70B Model: 2-3 months minimum
- GPT-4 Scale: 6+ months of continuous training
Fine-Tuning Timelines
The contrast is striking:
You can fine-tune a pre-trained BERT model for text classification in just a few hours, while training a large NLP model from scratch could take weeks in comparison.
A 7B model with QLoRA on an RTX 4090 may take 2-4 days for a full fine-tune run.
Timeline Breakdown:
- Parameter-Efficient Fine-Tuning (PEFT): Hours to days
- Full Fine-Tuning: Days to 1-2 weeks
- Training From Scratch: Weeks to months
Performance Comparison: Quality Matters
Let's address the elephant in the room: Does fine-tuning sacrifice quality for speed?
The data tells a compelling story:
OpenAI reports that GPT-3 fine-tuning can increase correct outputs from 83% to 95%, demonstrating significant improvements in task-specific accuracy.
When Fine-Tuning Outperforms Training From Scratch
Limited Data Scenarios:
Training a large model from scratch on a small dataset risks overfitting—the model might learn to perform well on training examples but generalize poorly to new data.
Domain Adaptation:
Fine-tuning consumes lower computational power and time, with models performing well in many cases even with little data, as pre-trained layers learn general features useful for most tasks.
Read More: Top 10 Benefits of Fine Tuning AI for Industry Specific Tasks
When Training From Scratch Wins
Unique Architectures:
Training from scratch allows complete control over model architecture, making it tailored specifically for the task, with no prior biases and no unwanted features inherited from pre-existing datasets.
Novel Domains:
When your data is fundamentally different from anything the model has seen before, the pre-trained knowledge may actually hinder performance.
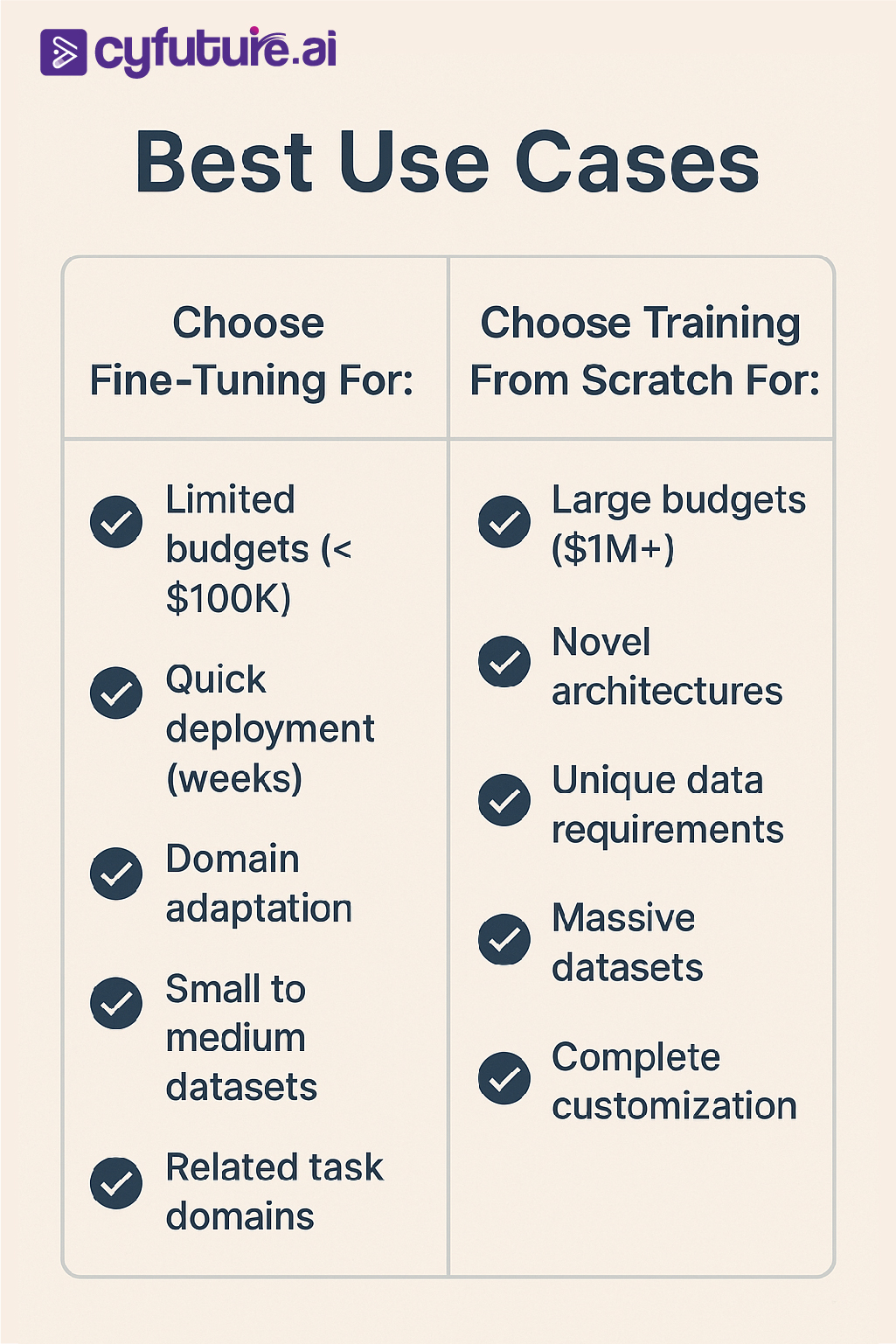
The Decision Framework: Choosing Your Path
Here's your practical decision matrix:
Choose Fine-Tuning When:
1. Limited Data Availability
You have thousands, not millions, of training examples. Fine-tuning works effectively even with little data as pre-trained layers have already learned general features useful for most tasks.
2. Time Constraints
You need to deploy within weeks, not months.
3. Budget Limitations
Fine-tuning is your go-to when you have limited time and resources and an existing model that can be adapted, allowing you to quickly customize a model to your specific needs.
4. Related Domain
Your task is similar to what pre-trained models already understand.
5. Resource Efficiency
Fine-tuning generally requires less time and computational resources compared to training a model from scratch since it starts with pre-existing weights and architectures.
Choose Training From Scratch When:
1. Unique Requirements
Training from scratch is particularly useful for tasks that require high flexibility and accuracy or tasks where no suitable pre-trained model exists, perfect for industries or applications involving unique or complex data.
2. Novel Architecture
You're developing new model architectures or experimental approaches.
3. Massive Dataset
You have millions of high-quality, labeled examples.
4. Complete Control
Training a model from scratch allows complete control over its architecture, ensuring the model doesn't inherit any biases or unwanted features from pre-existing datasets.
5. Research Goals
You're conducting academic research or publishing novel methods.
The Hybrid Approach: Best of Both Worlds
Smart teams don't always choose one or the other—they combine approaches strategically.
A hybrid strategy combining fine-tuning with RAG (Retrieval Augmented Generation) provides the accuracy of fine-tuned models along with the flexibility to handle real-time data, reducing the need for frequent retraining and lowering operational costs.
Implementation Strategy:
Phase 1: Foundation
Start with a pre-trained model closest to your domain.
Phase 2: Initial Fine-Tuning
Fine-tune on your specific dataset using parameter-efficient methods like LoRA.
Phase 3: Evaluation
Assess performance gaps.
Phase 4: Selective Training
If necessary, train specific components from scratch while keeping fine-tuned layers.
Parameter-Efficient Fine-Tuning: The Modern Solution
The AI landscape has evolved beyond the simple fine-tuning vs. training from scratch dichotomy. Enter parameter-efficient fine-tuning (PEFT).
Parameter-efficient fine-tuning methods like LoRA or QLoRA significantly reduce GPU memory requirements compared to fully supervised fine-tuning, making them the preferred approach for fine-tuning existing open-source LLMs.
Also check: Fine Tuning vs Serverless Inferencing: What Works Best for Real-World AI?
LoRA and QLoRA: Game Changers
These techniques allow you to fine-tune massive models on consumer-grade hardware. A LLaMA-2 7B model can be fine-tuned on a single NVIDIA RTX 4090 (24 GB) when using QLoRA.
Benefits of PEFT:
- Reduces memory requirements by 60-80%
- Maintains comparable performance to full fine-tuning
- Enables experimentation on limited hardware
- Faster training iterations
Common Pitfalls and How to Avoid Them
Fine-Tuning Mistakes:
1. Catastrophic Forgetting
Using too high a learning rate can cause the model to "forget" its pre-trained knowledge.
Solution: Use lower learning rates when fine-tuning, typically 1e-5 or 1e-6, to slowly fine-tune without significantly impacting already adjusted weights.
2. Overfitting on Small Datasets
There's an overfitting risk when training a model with a limited amount of data, requiring careful approaches to avoid overfitting the system.
Solution: Implement early stopping, use regularization techniques, and augment your dataset.
3. Domain Mismatch
Choosing a pre-trained model from a completely different domain.
Solution: Select foundation models trained on data similar to your use case.
Training From Scratch Mistakes:
1. Insufficient Data
Starting from scratch without millions of diverse examples.
Solution: Training from scratch requires a large, diverse dataset for optimal performance—ensure you have enough data before committing.
2. Poor Hyperparameter Tuning
Training from scratch requires in-depth knowledge of machine learning, model architecture, and optimization techniques, including expertise in hyperparameter tuning.
Solution: Invest in extensive hyperparameter search and ablation studies.
3. Ignoring Transfer Learning
Reinventing wheels that others have perfected.
Solution: Even when training from scratch, consider using proven architectural components.
Cyfuture AI: Your Partner in AI Excellence
At Cyfuture AI, we understand that choosing between fine-tuning and training from scratch isn't just a technical decision—it's a business strategy. Our platform provides:
- Flexible Infrastructure: Access to high-performance GPU clusters optimized for both fine-tuning and training from scratch
- Cost Optimization: Intelligent resource allocation that reduces your AI development costs by up to 60%
- Expert Guidance: Our AI specialists help you choose the right approach for your specific use case
- Rapid Deployment: Streamlined workflows that get your models from development to production faster
With Cyfuture AI's cutting-edge infrastructure and expertise, teams are deploying production-ready AI models 5x faster than traditional approaches, whether through fine-tuning or training from scratch.
Accelerate Your AI Journey With Strategic Model Training
The choice between fine-tuning and training from scratch isn't binary—it's strategic.
Smart AI teams in 2026 understand that success lies not in following dogmatic approaches but in aligning technical decisions with business objectives. Whether you choose the speed and efficiency of fine-tuning or the customization of training from scratch, what matters most is understanding your constraints, resources, and goals.

Frequently Asked Questions (FAQs)
Q1: How much data do I need for fine-tuning vs. training from scratch?
For fine-tuning, you can achieve good results with as few as 1,000-10,000 examples depending on the task. Training from scratch typically requires millions of diverse, high-quality examples to achieve comparable performance.
Q2: Can I fine-tune a model on a different domain than it was originally trained on?
Yes, but effectiveness varies. Fine-tuning works best when there's some overlap between the original and target domains. For completely different domains, you may need more data or consider training from scratch.
Q3: What are the minimum GPU requirements for fine-tuning a 7B parameter model?
The absolute minimum is around 12-16 GB VRAM when using QLoRA or other quantization methods, though 24 GB VRAM is considered realistic for most parameter-efficient fine-tuning setups.
Q4: How long does it typically take to fine-tune vs. train from scratch?
Fine-tuning can take hours to days, while training from scratch typically requires weeks to months. The exact timeline depends on model size, dataset size, and available compute resources.
Q5: Is fine-tuning always cheaper than training from scratch?
Generally, yes. Fine-tuning can cost around $10 compared to training from scratch which would require around 8,100 GPUs for ten days costing thousands of dollars. However, for very unique use cases, the cost difference may narrow.
Q6: Can fine-tuned models match the performance of models trained from scratch?
OpenAI reports that GPT-3 fine-tuning can increase correct outputs from 83% to 95%. For related tasks, fine-tuned models often match or exceed from-scratch performance while using far fewer resources.
Q7: What is parameter-efficient fine-tuning (PEFT) and should I use it?
PEFT methods like LoRA or QLoRA significantly reduce GPU memory requirements compared to fully supervised fine-tuning. If you have limited GPU resources, PEFT is highly recommended.
Q8: How do I know if my use case requires training from scratch?
Training from scratch is particularly useful for tasks that require high flexibility and accuracy or tasks where no suitable pre-trained model exists, perfect for industries or applications involving unique or complex data.
Q9: What's the difference between fine-tuning and transfer learning?
Transfer learning is when a model developed for one task is reused to work on a second task, while fine-tuning is one approach to transfer learning where you change the model output to fit the new task and train only the output model.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.