







































































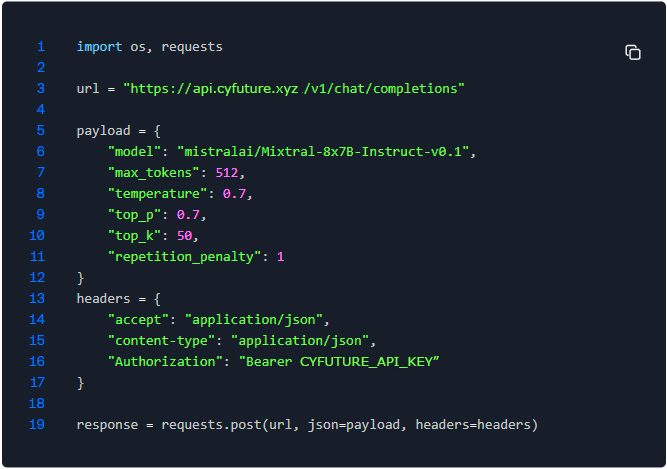














Why Cyfuture AI Stands Out
We've engineered a high-performance AI inference platform designed for seamless deployment, effortless scaling, and cost efficiency.
Serverless Inferencing
Cyfuture AI provides serverless Inferencing as a Service, allowing enterprises to deploy AI models without worrying about infrastructure. The AI Inference Service automatically manages scaling and resource allocation, delivering seamless, cost-efficient performance across cloud, edge, or on-premise environments.
Ultra-Low Latency
With AI Inference as a Service, Cyfuture AI delivers real-time predictions for mission-critical applications. Its advanced infrastructure ensures minimal latency, allowing businesses to make instant decisions while maintaining high accuracy and reliability for AI-driven operations.
Scalable Workload Management
Cyfuture AIâs Inferencing as a Service platform intelligently distributes workloads across CPU and GPU resources. The AI Inference Service ensures smooth performance during peak demand, enabling enterprises to scale applications efficiently without downtime or slowdowns.
Cost Optimization
With Inference as a Service (IaaS), enterprises pay only for what they use. Cyfuture AI eliminates costly on-premise hardware and lowers operational expenses, offering a cost-efficient, scalable solution for running AI workloads.
Comprehensive Monitoring & Insights
AI Inference Service includes real-time dashboards for monitoring models, inference requests, and performance metrics. Enterprises gain visibility into resource usage and AI operations, enabling informed decision-making and proactive maintenance with minimal administrative effort.
Framework Deployment Flexibility
Cyfuture AI supports multiple AI frameworks and deployment environments. Its Inferencing-as-a-Service enables enterprises to run models seamlessly on cloud, edge, or on-premise, maximizing adaptability and accelerating time-to-value.













