




































































The AI infrastructure landscape of 2026 has reached an inflection point. As organizations racing to deploy large language models, multi-modal AI applications, and real-time inference systems face an unavoidable question: when does a single GPU server become a bottleneck, and when should you invest in a GPU cluster? This decision, worth potentially millions in infrastructure costs, determines not just your computational capacity but your competitive edge in the AI revolution.
According to research from Epoch AI, the global GPU cluster landscape now encompasses over 500 documented facilities, with aggregate performance growing exponentially. Training sophisticated models like GPT-3 required thousands of petaflop/s-days powered by extensive GPU clusters—a scale impossible with single-server architectures. Yet for many workloads, clusters remain overkill. Understanding this distinction has become mission-critical for tech leaders navigating 2026's AI infrastructure decisions.
Understanding Single GPU Servers: The Foundation
Architecture and Capabilities
Single GPU servers represent the entry point for most AI/ML initiatives. These systems typically house 1-4 high-performance GPUs within a single chassis, offering immediate computational power without complex orchestration requirements. Modern single-GPU configurations feature NVIDIA H100 (80GB HBM3), A100 (40GB/80GB), or AMD MI300X GPUs, delivering substantial processing capabilities for focused workloads.
The architectural simplicity of single GPU servers provides distinct advantages. Development teams access GPU resources directly without managing distributed systems, data scientists prototype models with minimal infrastructure overhead, and organizations avoid the complexity of cluster management software and high-speed interconnects.
Performance Metrics
Single GPU servers excel at specific computational profiles. An NVIDIA H100 GPU delivers up to 30X faster inference for large language models compared to previous generations, with fourth-generation Tensor Cores providing specialized acceleration for transformer architectures. For workloads fitting within 80GB VRAM boundaries, single GPUs offer remarkable efficiency.
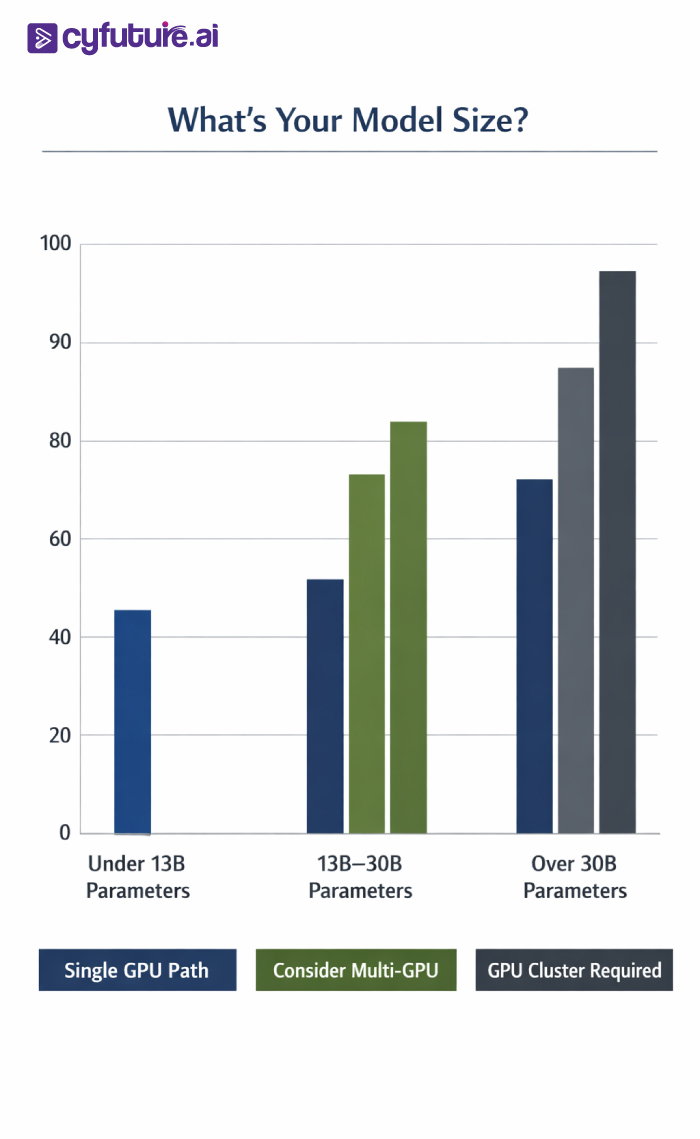
Industry benchmarks demonstrate that fine-tuning open-source LLMs up to 13B parameters succeeds on single A100 80GB GPUs using techniques like LoRA or QLoRA. Real-world inference deployments handle thousands of simultaneous requests on individual high-end GPUs, particularly when models are optimized for FP8 or INT8 precision.
Cost Considerations
The economics of single GPU servers appear straightforward but demand careful analysis. Cloud providers charge $2.25-$3.99 per hour for H100 instances as of January 2026, with A100 availability at $2.00-$2.99 hourly. For organizations with consistent 24/7 workloads exceeding 40 hours monthly, purchasing dedicated hardware becomes economically viable—though single H100 GPUs cost $25,000-$40,000 each, requiring substantial capital investment.
GPU Clusters: Scaling for Enterprise AI
Cluster Architecture Fundamentals
GPU clusters represent distributed computing infrastructure where multiple GPU-equipped servers work collaboratively. Modern clusters range from 8-GPU configurations to massive installations exceeding 100,000 GPUs, as evidenced by the DOE's planned Solstice system featuring 100,000 NVIDIA Blackwell GPUs expected in 2026.
Essential cluster components include worker nodes equipped with 4-8 GPUs per server handling compute-intensive tasks, head nodes managing orchestration, job scheduling, and resource allocation, and high-speed interconnects utilizing InfiniBand (200-400 Gbps), NVLink (900 GB/s for H100), or emerging UALink standards providing low-latency communication between nodes.
Research data confirms that adding GPU nodes to clusters increases throughput performance linearly—a critical advantage over CPU cluster scaling patterns. This linear scalability makes clusters exceptionally cost-effective for workloads requiring sustained parallel processing.
Performance at Scale
The computational advantages of GPU clusters become undeniable for frontier AI workloads. Training large language models beyond 30B parameters necessitates distributed architectures. According to industry analysis, GPT-3 training consumed thousands of petaflop/s-days—computationally infeasible on single servers.
GPU clusters deliver over 200% faster performance compared to CPU-based systems for AI workloads, according to recent Datadog performance reports. For production AI inference serving millions of daily requests, clusters provide horizontal scalability that single servers cannot match, distributing workload across multiple nodes to prevent bottlenecks and ensure consistent latency.
Modern cluster architectures increasingly leverage specialized interconnect technologies. NVIDIA's NVLink dominates scale-up connectivity in 2026, with Blackwell NVL72 extending tightly-coupled GPU communication to entire racks (72 GPUs), and future Rubin architectures planning NVL576 configurations connecting nearly 600 GPUs in unified scale-up domains.
Read More: Buy GPU Server in India: Pricing, Warranty & Delivery
Infrastructure and Operational Costs
Building GPU clusters demands significant investment beyond GPU hardware. Infrastructure expenses include InfiniBand networking costing $2,000-$5,000 per node, with switches ranging $20,000-$100,000 depending on port count and bandwidth requirements. Power infrastructure supporting each H100's 700W consumption necessitates dedicated power distribution units, potentially requiring facility upgrades adding $10,000-$50,000 to deployment costs.
For an 8-GPU cluster using A100 accelerators, total hardware investment reaches $120,000-$200,000 for GPUs alone. Infrastructure costs often match or exceed GPU expenses, making production-ready cluster deployment substantially higher than base hardware pricing suggests.
Operational expenses prove equally substantial. GPU clusters demand significant power and cooling—training workloads consume up to 1 megawatt per rack in frontier systems requiring ultra-dense GPU stacks and liquid cooling. Inference workloads, while less demanding, still operate at 30-150 kilowatts per rack—dramatically above traditional compute infrastructure.
Making the Scaling Decision: Critical Factors
Workload Characteristics
The fundamental scaling decision hinges on workload analysis. Single GPU servers suffice when model size fits within individual GPU memory (typically 80GB for modern high-end GPUs), training datasets remain manageable for single-node processing, inference requests stay within single-GPU throughput capacity, and development/prototyping workflows don't require massive parallelization.
GPU clusters become necessary when training foundation models exceeding 30B parameters, processing datasets requiring distributed storage and parallel loading, serving production inference at scale with millions of daily requests, running continuous 24/7 workloads justifying infrastructure investment, and requiring fault tolerance and redundancy for mission-critical applications.
Time-to-Results Requirements
Organizations face distinct temporal pressures. Training cycles become competitive differentiators—reducing model training from weeks to days can accelerate time-to-market significantly. According to infrastructure trends, 74% of organizations now prefer hybrid cloud approaches (on-premises plus public cloud or multi-cloud) versus only 4% choosing purely on-premises infrastructure.
For time-sensitive research or rapid iteration cycles, cloud-based GPU clusters offer immediate scalability without procurement delays. Cyfuture AI enables organizations to scale from single GPUs to multi-GPU clusters effortlessly, with deployment times reduced to minutes rather than weeks of traditional hardware procurement.
Budget and TCO Analysis
Total cost of ownership calculations must encompass all infrastructure layers. Cloud GPU clusters eliminate capital expenditure with pay-as-you-go models, avoid infrastructure management overhead, and provide flexible scaling matching actual workload demands. Cyfuture AI's transparent GPU as a Service pricing reduces infrastructure costs by up to 70% compared to on-premises ownership while providing cutting-edge GPU hardware access.
On-premises clusters deliver long-term cost advantages for sustained 24/7 workloads but demand substantial upfront capital, require dedicated IT staff for maintenance and management, and carry depreciation risk as GPU technology evolves rapidly. The breakeven point typically occurs around 12-18 months of continuous utilization.
Organizational Maturity
Technical capability and operational maturity influence optimal infrastructure choices. Organizations with limited GPU expertise benefit from managed GPU cloud services, while teams possessing deep infrastructure knowledge can optimize on-premises clusters for specific workload profiles.
Cyfuture AI serves organizations across the maturity spectrum—from startups requiring simple GPU access for prototyping to enterprises demanding custom-configured clusters for production AI deployments. With pre-configured environments optimized for popular ML frameworks, Cyfuture AI enables model deployment 5X faster than conventional cloud solutions.

Hybrid Approaches: The Modern Solution
Strategic Infrastructure Mixing
Leading organizations increasingly adopt hybrid strategies rather than choosing exclusively between single GPUs and clusters. Effective hybrid models utilize on-premises single GPU servers for development and experimentation, cloud-based GPU clusters for burst capacity during training cycles, and reserved cluster capacity for production inference serving consistent baseline loads.
This approach optimizes both cost and performance. Development teams iterate rapidly on accessible hardware while production workloads leverage appropriate scale without over-provisioning infrastructure.
Multi-Cloud and Flexibility
Multi-cloud GPU strategies prevent vendor lock-in while optimizing costs across providers. Organizations can access specialized GPU types from different providers based on workload requirements, leverage spot instances and preemptible VMs for cost-sensitive non-critical workloads, and maintain geographic distribution for latency optimization and regulatory compliance.
Cyfuture AI's GPU as a Service supports seamless multi-cloud integration, allowing enterprises to implement sophisticated hybrid strategies without infrastructure management complexity.

Future Infrastructure Trends
The AI infrastructure landscape continues rapid evolution. NVIDIA's roadmap extends scale-up architectures dramatically—from current NVL72 configurations to planned NVL576 systems connecting hundreds of GPUs in unified domains. Alternative interconnect standards like UALink, developed by AMD and industry partners, promise competitive options reducing NVIDIA dependency.
Energy efficiency becomes increasingly critical as training workloads approach megawatt-per-rack power consumption. Advanced cooling technologies including liquid cooling and immersion systems enable higher density deployments while managing operational costs.
Inference economics increasingly drive infrastructure decisions as organizations shift from model training focus to always-on, continuous inference at production scale. Specialized inference architectures optimized for atomizable workloads promise superior cost-efficiency compared to training-optimized clusters.
Cyfuture AI: Your Scaling Partner
Cyfuture AI empowers organizations to navigate GPU infrastructure complexity with confidence. Our GPU as a Service platform delivers NVIDIA A100, H100, and V100 GPU access with flexible configurations from single instances to large-scale clusters. Transparent pricing models enable accurate TCO forecasting, while pre-optimized ML framework environments accelerate deployment timelines.
With infrastructure costs reduced up to 70% compared to traditional hardware investments and deployment times compressed from weeks to minutes, Cyfuture AI bridges the gap between infrastructure requirements and business realities. Whether you're a startup prototyping AI applications or an enterprise deploying production-scale inference systems, Cyfuture AI provides the infrastructure foundation for success.

Frequently Asked Questions
Q: How many GPUs do I need for training a large language model?
A: Models up to 13B parameters can train on single A100 80GB GPUs using optimization techniques like LoRA. Models exceeding 30B parameters require multi-GPU configurations or clusters. For frontier models approaching 100B+ parameters, clusters with dozens to hundreds of GPUs become necessary. The exact requirement depends on model architecture, precision (FP16 vs FP8), and available VRAM.
Q: What's the cost difference between cloud GPU clusters and owned infrastructure?
A: Cloud GPU clusters typically cost $2.25-$3.99 per hour per H100 GPU (January 2026 rates), with no upfront investment. Owned infrastructure requires $25,000-$40,000 per H100 GPU plus networking ($2,000-$5,000 per node) and facility costs ($10,000-$50,000). The breakeven point for 24/7 workloads occurs around 12-18 months, but cloud provides flexibility for variable workloads and eliminates management overhead.
Q: Can I start with a single GPU and scale to clusters later?
A: Absolutely. Most successful AI organizations begin with single GPU development environments and scale to clusters as workload demands grow. Cloud-based GPU services like Cyfuture AI enable seamless scaling from single GPUs to multi-GPU clusters without infrastructure redesign, allowing you to match resources to actual requirements dynamically.
Q: What interconnect technology should GPU clusters use in 2026?
A: For NVIDIA-based clusters, NVLink provides 900 GB/s bandwidth on H100 systems with proven maturity. InfiniBand offers 200-400 Gbps networking for multi-node communication with low latency. Emerging UALink standards promise competitive alternatives supporting up to 1,024 accelerators in unified scale-up systems. The optimal choice depends on GPU vendor, cluster size, and workload communication patterns.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.