




































































Introduction: The H200 Revolution Reshaping AI Infrastructure
Imagine deploying a 70-billion-parameter language model on a single GPU without the complexity of multi-GPU tensor parallelism. This isn't a future scenario—it's the reality the NVIDIA H200 GPU delivers today. As AI models push beyond 100 billion parameters and enterprises race to deploy generative AI at scale, the H200 has emerged as the critical infrastructure piece bridging the gap between computational ambition and practical deployment.
With 141GB of HBM3e memory and 4.8 TB/s bandwidth, the H200 represents NVIDIA's most significant memory upgrade in the Hopper architecture family. But beyond the impressive specifications lies a complex procurement landscape shaped by geopolitical tensions, supply chain dynamics, and evolving market demand. Whether you're a CTO planning 2026 infrastructure investments or a researcher seeking cutting-edge compute resources, understanding H200 pricing, availability, and lead times is essential for strategic decision-making.
NVIDIA H200 GPU Pricing: Complete Cost Analysis
Outright Purchase Pricing
As of January 2026, the Buy NVIDIA H200 GPU commands premium pricing that reflects its advanced capabilities and market positioning.
Single GPU Units:
- H200 NVL (PCIe): $31,000-$40,000 per unit
- H200 SXM5: Not available as single unit (sold in multi-GPU configurations only)
Multi-GPU Configurations:
- 4-GPU SXM board: Approximately $175,000
- 8-GPU SXM board: $308,000-$315,000
These figures represent a 30-50% premium over comparable H100 configurations, justified by the substantial memory and bandwidth improvements. An 8-GPU H100 board typically costs around $216,000, making the H200 upgrade a significant but proportional investment for organizations requiring maximum memory capacity.
Cloud Rental Pricing: Pay-as-You-Go Models
For enterprises seeking flexibility without capital expenditure, cloud-based H200 rental presents compelling economics. Current market rates as of January 2026 show considerable variation across providers:
Major Cloud Providers (per GPU/hour):
- Google Cloud Spot: $3.72 (preemptible, lowest rate)
- Jarvislabs: $3.80 (single GPU access, on-demand)
- AWS: $4.50-$5.20 (balanced availability and pricing)
- Fluence (decentralized): $2.53-$2.80 (emerging competitive option)
- Oracle Cloud: $8.50-$9.00
- Azure: $10.60 (highest, enterprise-grade SLAs)
Critical Pricing Note: Most hyperscalers bundle H200s in 8-GPU instances only, with GPU pricing calculated by dividing total instance cost. Jarvislabs and select providers offer single-GPU access—crucial for prototyping and development workflows where full 8-GPU instances would be cost-prohibitive.
Total Cost of Ownership Considerations
When evaluating H200 investments, forward-thinking organizations analyze beyond sticker price:
Hidden Cloud Costs:
- Data egress charges (can add 15-30% to compute costs)
- Storage costs for large model checkpoints
- Network transfer fees for distributed training
- Cold start times affecting billable hours
Hardware Ownership Costs:
- Power consumption: 600W (NVL) to 700W (SXM) per GPU
- Cooling infrastructure requirements
- Data center space and rack costs
- Maintenance and replacement planning
Industry analysis suggests that for continuous workloads running 24/7, hardware ownership becomes cost-effective after 12-14 months compared to on-demand cloud pricing. However, for bursty or experimental workloads, cloud rental maintains clear advantages.
H200 GPU Availability and Market Dynamics in 2026
Current Supply Status
The H200 availability landscape in early 2026 reflects a transitional period as NVIDIA shifts focus toward next-generation Blackwell architecture:
Inventory Dynamics: NVIDIA currently holds approximately 700,000 H200 units in inventory, with major cloud providers having secured significant allocations. However, production has been scaled back as manufacturing capacity transitions to Blackwell B100/B200 GPUs. This creates a unique window where H200 availability is good but not expected to expand significantly.
Geographic Availability:
- North America: Strong availability through all major cloud providers and OEMs
- Europe: Good availability with 10-20% regional price premiums
- Asia-Pacific: Variable, with China representing unique dynamics (discussed below)
- Middle East: Growing availability as regional hyperscalers invest in AI infrastructure
China Market: A Special Case
A significant development in late 2025/early 2026 has been the US government's conditional approval for H200 exports to China, representing a major policy reversal. Key facts:
- Trump administration approved H200 sales with 25% revenue fee to US Treasury
- Initial shipments of 40,000-80,000 units planned for February 2026
- Chinese tech giants (Alibaba, ByteDance, Tencent) have ordered 2+ million units for 2026 delivery
- TSMC production capacity expansion planned for Q2 2026 to meet demand
- Beijing approval still pending but expected given domestic chip performance gap
This development could significantly impact global availability. Expert analysis suggests lead times for enterprise buyers may extend from current 4-8 weeks to 6-9 months if Chinese orders materialize at projected scales.
Cloud vs. Hardware Availability
Immediate Availability (0-2 weeks):
- Cloud instances from major providers (AWS, Azure, GCP, Oracle)
- Single-GPU access from specialized providers (Jarvislabs, Fluence)
- Spot/preemptible instances (subject to availability)
Medium Lead Time (4-8 weeks):
- Direct purchases from NVIDIA partners for standard configurations
- Custom OEM builds with standard specifications
- Reserved cloud capacity commitments
Extended Lead Time (2-4 months):
- Custom multi-GPU configurations requiring specific networking
- Large-scale enterprise orders (50+ GPUs)
- Specialized cooling or power configurations

Lead Time Analysis: Planning Your H200 Procurement
Current Lead Times by Purchase Type
Understanding procurement timelines is critical for infrastructure planning in 2026:
Immediate Access (Same Day - 1 Week):
- Cloud GPU instances from established providers
- Pre-configured instances with standard software stacks
- Spot/preemptible instances (when available)
Standard Hardware Orders (4-8 Weeks):
- Single H200 NVL units from authorized distributors
- Standard 4-GPU or 8-GPU SXM configurations
- OEM server builds with H200 integration
Custom Configurations (8-16 Weeks):
- Custom NVLink topologies
- Specialized server chassis requirements
- Large cluster deployments requiring coordination
- Integrated liquid cooling solutions
Extended Timelines (4-6 Months+):
- Orders placed after Chinese market opening (Q2 2026+)
- Highly customized data center integrations
- New production capacity allocation (requires TSMC manufacturing slots)
Factors Affecting Lead Times in 2026
Supply Chain Considerations:
- HBM3e Memory Availability: The H200's 141GB HBM3e memory represents advanced packaging technology with limited suppliers. High-bandwidth memory shortages could extend lead times by 4-8 weeks.
- Blackwell Transition: As NVIDIA prioritizes Blackwell production, H200 manufacturing slots become more competitive. Organizations requiring H200 specifically should secure orders before Q3 2026.
- Chinese Market Impact: If Beijing approves the 2+ million unit orders from Chinese enterprises, global lead times will likely extend significantly in H2 2026.
- Hyperscaler Priority: NVIDIA typically allocates GPUs to major cloud providers first, meaning enterprise direct purchases may face longer waits during high-demand periods.
Strategic Procurement Recommendations
For enterprises planning 2026 AI infrastructure:
Immediate Action Items:
- Pre-book allocation slots with preferred vendors for Q2-Q3 delivery
- Establish framework agreements with fixed pricing to hedge against potential increases
- Consider hybrid strategies: cloud for bursting, owned hardware for baseline workloads
Risk Mitigation:
- Diversify across multiple suppliers to reduce single-point dependency
- Evaluate H100 inventory availability as backup (still excellent for <100B parameter models)
- Monitor Blackwell availability timelines (may offer better long-term value)
Budget Planning:
- Anticipate 10-15% price volatility through 2026 based on demand fluctuations
- Account for potential lead time premium charges (5-10% for expedited delivery)
- Factor integration costs: software optimization, data migration, staff training
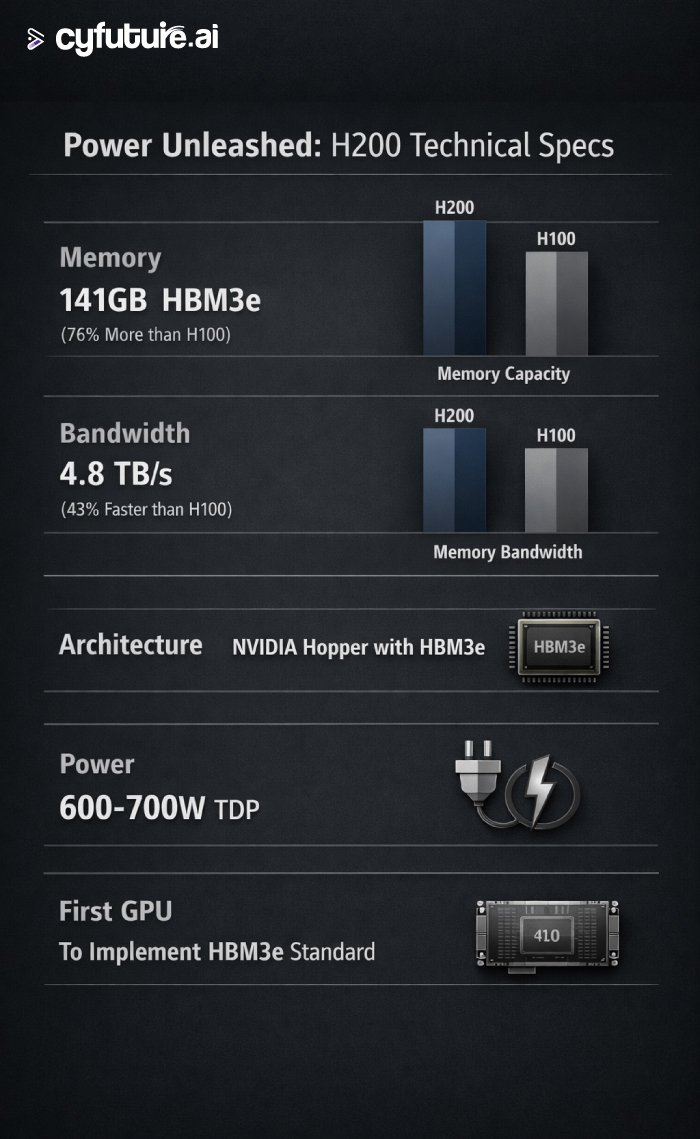
H200 Performance Specifications and Value Proposition
Technical Specifications Breakdown
Memory Architecture:
- Capacity: 141GB HBM3e (76% increase over H100's 80GB)
- Bandwidth: 4.8 TB/s (43% increase over H100's 3.35 TB/s)
- Technology: First GPU to implement HBM3e standard
Compute Performance:
- FP64 performance: Identical to H100
- FP32/TF32 performance: Identical to H100
- FP8 Tensor performance: Up to 1.9x faster than H100 for inference workloads
- Power efficiency: Same 600-700W envelope as H100
Key Insight: The H200 delivers performance gains specifically for memory-bound workloads. For compute-bound tasks, performance matches H100. This makes workload characterization essential for ROI analysis.
Real-World Performance Benchmarks
Large Language Model Inference:
- Llama 2 70B: 1.9x faster than H100 GPU at full precision
- GPT-3 175B: 1.6x throughput improvement (8-GPU configuration)
- DeepSeek-R1 671B: Deployable on 8xH200 (impossible on H100)
Training Workloads:
- Memory-bound tasks: Up to 1.4x faster training times
- Compute-bound tasks: Equivalent to H100 performance
- Extended context windows (32K+ tokens): 45% faster attention operations
HPC Applications:
- Molecular dynamics: 30-35% faster time-to-solution
- Financial risk models: 40% performance improvement
- Weather simulations: 25-30% acceleration for memory-intensive scenarios
When H200 Makes Strategic Sense
Optimal Use Cases:
- Training or fine-tuning models exceeding 70B parameters
- Inference serving for 100B+ parameter models
- Extended context length applications (>16K tokens)
- Multi-modal models requiring large memory footprints
- Scientific simulations with memory bandwidth bottlenecks
When H100 Suffices:
- Models under 70B parameters
- Inference-optimized smaller models
- Compute-bound training workloads
- Budget-constrained prototyping
- Workloads with <8K context windows
Cyfuture AI: Accelerating Your H200 Deployment
As organizations navigate the complex H200 procurement landscape, partnering with experienced infrastructure providers delivers measurable advantages. Cyfuture AI has established itself as a leading GPU cloud services provider with demonstrated value in AI acceleration.
Cyfuture AI's H200 Advantages
Cost Optimization: Cyfuture AI delivers up to 73% cost savings versus major hyperscalers on H100 configurations, with competitive H200 GPU pricing structures expected to maintain similar advantages. Their transparent GPU as a Service pricing model eliminates hidden costs that can inflate cloud computing expenses by 20-30%.
Deployment Velocity: Organizations deploying AI models on Cyfuture AI's platform achieve 5x faster time-to-production compared to traditional cloud solutions, thanks to pre-optimized environments with PyTorch, TensorFlow, and CUDA libraries already configured.
Infrastructure Reliability:
- 99.9% uptime SLA ensures mission-critical workloads remain operational
- Tier III+ data centers with redundant power and cooling
- 24/7 technical support with GPU infrastructure specialists
- Comprehensive security: SOC 2, ISO 27001, GDPR compliance
Flexible Deployment Models:
- Single-GPU access for development and prototyping
- Multi-GPU clusters for large-scale training
- Hybrid cloud integration for bursting workloads
- Serverless inferencing for production deployments
Strategic Consulting Services
Beyond infrastructure provisioning, Cyfuture AI provides expert guidance for:
- Workload optimization and GPU selection
- Cost modeling and resource allocation
- Migration from on-premise to cloud GPU environments
- Performance tuning and framework optimization
This consulting approach helps organizations avoid common pitfalls: over-provisioning expensive resources, selecting suboptimal GPU types, or underestimating data transfer costs—mistakes that can inflate AI infrastructure spending by 30-40%.

2026 Market Outlook
Pricing Trends: Industry analysis suggests H200 pricing will decline 10-15% through 2026 as Blackwell availability increases. Organizations with flexibility might benefit from waiting, while those with immediate needs should secure allocation now.
Availability Forecast: Lead times expected to tighten in Q2-Q3 2026 if Chinese market approvals materialize. Enterprise buyers should plan accordingly and establish vendor relationships proactively.
Technology Roadmap: Blackwell B100/B200 GPUs represent next-generation performance but won't achieve volume availability until late 2026/early 2027. The H200 remains the optimal choice for near-term (6-12 month) deployments.
Conclusion: Strategic H200 Procurement in 2026
The NVIDIA H200 GPU represents a pivotal technology for organizations deploying large-scale AI workloads in 2026. With 141GB of HBM3e memory and 4.8 TB/s bandwidth, it uniquely enables single-GPU deployment of 70B+ parameter models while delivering up to 1.9x inference performance improvements over the H100.
However, the procurement landscape requires careful navigation. Pricing ranges from $31,000-$40,000 for single units to over $300,000 for 8-GPU configurations. Cloud rental options span $2.53-$10.60 per GPU hour depending on provider and service level. Lead times currently sit at 4-8 weeks for standard orders but may extend to 6-9 months if projected Chinese demand materializes.
For enterprises planning 2026 AI infrastructure, the strategic imperative is clear: act decisively now to secure allocation, carefully evaluate total cost of ownership across rental and purchase options, and partner with experienced providers who can optimize deployment economics and accelerate time-to-value.

Frequently Asked Questions
Q: What's the price difference between H200 and H100 GPUs?
A: The H200 commands a 30-50% premium over H100 configurations. Single H200 NVL units cost $31,000-$40,000 versus $25,000-$30,000 for H100 equivalents. For 8-GPU configurations, expect $308,000-$315,000 (H200) versus $216,000 (H100). This premium reflects 76% more memory (141GB vs 80GB) and 43% higher bandwidth.
Q: How long does it take to receive H200 GPUs after ordering?
A: Lead times vary significantly by purchase type. Cloud instances are available immediately. Standard hardware orders require 4-8 weeks. Custom configurations need 8-16 weeks. However, if Chinese market orders materialize as projected, lead times could extend to 6-9 months in H2 2026. Enterprises should pre-book allocation slots now to avoid delays.
Q: Is it better to rent or buy H200 GPUs in 2026?
A: This depends on utilization patterns. For 24/7 continuous workloads, hardware ownership becomes cost-effective after 12-14 months. For bursty or experimental workloads, cloud rental offers superior economics. A hybrid strategy—owned hardware for baseline capacity, cloud for peak demands—often optimizes both cost and flexibility. Cyfuture AI consulting services can model your specific scenario.
Q: Will H200 availability be affected by exports to China?
A: Yes, potentially significantly. Chinese enterprises have ordered 2+ million H200 units for 2026 delivery, far exceeding NVIDIA's current inventory of 700,000 units. If Beijing approves these purchases, global lead times will likely extend from current 4-8 weeks to 6-9 months. TSMC is expanding production capacity in Q2 2026, but this represents a major demand surge without immediate supply increase. Enterprises should secure orders before Q2 2026 to avoid extended timelines.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.