




































































The artificial intelligence revolution demands unprecedented computational power. As enterprises race to deploy large language models (LLMs), generative AI applications, and sophisticated deep learning systems, the NVIDIA H100 GPU has emerged as the undisputed leader in AI infrastructure. But is it the right investment for your organization? This comprehensive guide explores everything you need to know about acquiring H100 GPUs for your AI workloads.
Understanding the NVIDIA H100: The AI Powerhouse
The NVIDIA H100, built on the revolutionary Hopper architecture, represents a quantum leap in AI computing capabilities. Available in two primary variants—H100 SXM and H100 PCIe—this GPU delivers exceptional performance across all AI workloads. The H100 SXM offers superior performance with 700W TDP and faster NVLink connectivity, while the PCIe version provides flexibility for standard server integration at 350W.
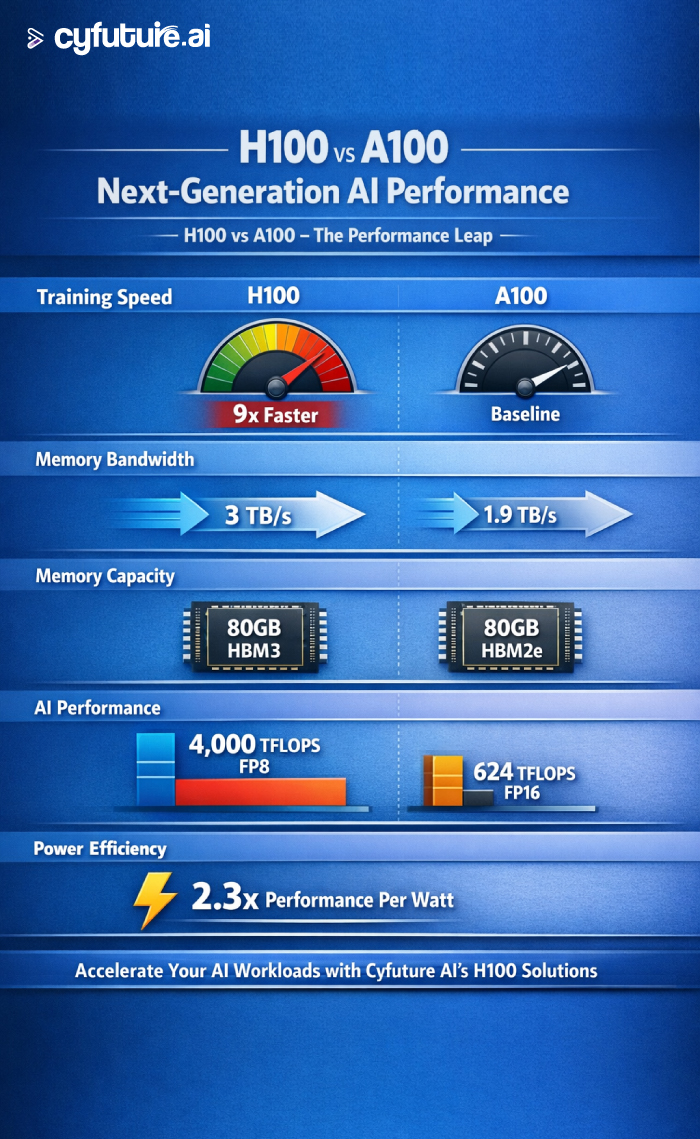
What sets the H100 apart is its purpose-built design for AI. With 80GB of HBM3 memory delivering 3TB/s bandwidth, the Transformer Engine optimized for LLM training, and native FP8 precision support, the H100 achieves up to 9x faster AI training compared to its predecessor, the A100. For organizations running cutting-edge AI workloads, these specifications translate directly into faster model training, reduced inference latency, and ultimately, competitive advantage.

Why H100 Excels for Large Language Models
Large language models have transformed how we interact with technology, but they demand enormous computational resources. The H100's architecture addresses these demands head-on. Training models like GPT-4, LLaMA, or custom enterprise LLMs requires massive parallel processing capabilities and substantial memory bandwidth—precisely what the H100 delivers.
The GPU's Multi-Instance GPU (MIG) technology allows a single H100 to be partitioned into up to seven independent instances, enabling multiple smaller models or inference tasks to run simultaneously. This flexibility maximizes utilization and improves cost efficiency, particularly for organizations running diverse AI workloads. For inference operations, the H100 processes tokens at unprecedented speeds, reducing latency and enabling real-time AI applications that were previously impractical.
Read More: What Makes the NVIDIA H100 the Top Choice for LLM Training
Generative AI and Deep Learning Performance
Beyond LLMs, the H100 excels across the entire generative AI spectrum. Whether you're generating high-resolution images with Stable Diffusion, creating videos, or building multi-modal AI applications, the H100's raw computational power and memory capacity ensure smooth, efficient processing. Organizations leveraging generative AI for content creation, product design, or customer engagement find the H100's performance transformative.
For traditional deep learning workloads—computer vision, recommendation systems, fraud detection—the H100's mixed-precision training capabilities accelerate model development cycles. Teams can iterate faster, experiment with larger models, and deploy more accurate solutions. When scaled across multiple H100s using NVLink and NVSwitch interconnects, training times for massive datasets decrease dramatically, turning weeks-long training runs into days or hours.

Navigating Your H100 Purchase Options
Acquiring H100 GPUs requires careful consideration of your deployment model. Organizations face three primary pathways: cloud-based access, on-premises purchase, or GPU-as-a-Service platforms.
Cloud providers like AWS, Microsoft Azure, Google Cloud, and Oracle Cloud offer H100 instances, providing immediate access without capital expenditure. This approach suits organizations testing AI capabilities, handling variable workloads, or avoiding infrastructure management overhead. However, long-term cloud costs can exceed on-premises investment for sustained, high-utilization scenarios.
On-premises H100 deployment offers maximum control, enhanced data security, and potentially lower total cost of ownership for organizations with consistent, heavy AI workloads. However, this path requires significant upfront investment—a single H100 GPU costs between $30,000-$40,000, with complete server configurations (typically 8-GPU setups) ranging from $250,000 to $400,000. Additionally, you must account for power infrastructure (each 8-GPU server draws 5-7kW), cooling systems, and networking equipment.
GPU-as-a-Service platforms present a middle ground, offering dedicated H100 access with flexible commitment terms. This model provides predictable costs without the infrastructure burden, ideal for growing AI teams or organizations with project-based AI initiatives.
Total Cost of Ownership Analysis
Smart H100 purchasing decisions extend beyond sticker prices. A comprehensive TCO analysis considers hardware costs, power consumption (the H100's efficiency actually reduces per-computation energy costs despite high absolute power draw), cooling infrastructure, networking equipment, and ongoing maintenance.
For organizations running LLM inference serving hundreds of thousands of daily requests, on-premises H100 infrastructure often pays for itself within 18-24 months compared to cloud costs. Conversely, research teams running occasional training experiments benefit from cloud flexibility without stranded capacity during idle periods.
Infrastructure requirements demand attention too. H100 servers require robust power delivery, enterprise-grade cooling, and high-bandwidth networking for multi-GPU configurations. Data centers must provide adequate PDU capacity, cold aisle/hot aisle arrangements, and typically 100Gbps+ networking for optimal performance.
Making the Right Choice for Your Organization
Choosing H100 GPUs isn't one-size-fits-all. Organizations training large proprietary LLMs or running high-volume inference workloads find H100s indispensable. The performance advantages directly impact time-to-market for AI products and services. For smaller-scale applications, considering alternatives like NVIDIA A100, H100 PCIe variants, or waiting for newer H200 GPU releases might offer better value propositions.
The key lies in matching GPU capabilities to actual workload requirements. Cyfuture AI specializes in helping organizations navigate these decisions, conducting workload assessments, performance modeling, and ROI analysis to ensure your GPU investment aligns perfectly with your AI strategy.

Conclusion: Investing in AI's Future
The H100 GPU represents more than powerful hardware—it's an enabler of AI innovation. Organizations that deploy H100 infrastructure position themselves at the forefront of the AI revolution, capable of training cutting-edge models, deploying responsive generative AI applications, and extracting maximum value from their data assets.
Whether you choose cloud access, on-premises deployment, or hybrid approaches, the critical factor is aligning your GPU strategy with business objectives. As AI continues reshaping industries, having the computational foundation to compete becomes non-negotiable. The H100 provides that foundation, delivering the performance, efficiency, and scalability required for tomorrow's AI challenges today.
Read More: H100 GPU Price in India (2026): PCIe vs SXM, Exact Price Range, Specs & Use Cases
FREQUENTLY ASKED QUESTIONS
1. What is the difference between H100 SXM and H100 PCIe variants?
Answer: The H100 SXM and PCIe variants differ primarily in power delivery, cooling, and interconnect capabilities. The H100 SXM variant offers superior performance with a 700W TDP, faster NVLink connectivity (900 GB/s), and is designed for high-density server configurations. It requires specialized server designs with direct liquid cooling or advanced air cooling solutions.
The H100 PCIe variant operates at 350W TDP, fits standard PCIe 5.0 slots, and provides more flexibility for integration into existing server infrastructure. While it delivers slightly lower performance than SXM, it's easier to deploy and doesn't require specialized cooling infrastructure. For maximum performance in multi-GPU configurations and large-scale AI training, choose SXM. For easier integration and retrofit scenarios, PCIe is more practical.
2. How many H100 GPUs do I need for training large language models?
Answer: The number of H100 GPUs required depends on your model size, dataset, and time constraints. For fine-tuning smaller models (7B-13B parameters like LLaMA-2), a single H100 can suffice, completing training in days. Mid-size models (30B-70B parameters) typically require 4-8 H100 GPUs for practical training timelines.
For training truly large models (100B+ parameters) from scratch, you'll need 16-64+ H100 GPUs in multi-node configurations. For reference, models like GPT-3 scale required thousands of GPUs, though the H100's improved efficiency reduces these numbers significantly compared to previous generations. Cyfuture AI can conduct workload analysis to determine the optimal GPU count for your specific model architecture and training objectives, balancing performance with budget constraints.
3. Is it more cost-effective to buy H100 GPUs or use cloud services?
Answer: The cost-effectiveness depends on your usage patterns and duration. Cloud services excel for short-term projects, variable workloads, or testing scenarios where you need immediate access without capital expenditure. If you're running AI workloads sporadically or for less than 30-40% of the time, cloud typically offers better economics.
However, for sustained, high-utilization scenarios (60%+ utilization), on-premises H100 infrastructure usually achieves better total cost of ownership within 18-24 months. Organizations running continuous LLM inference, ongoing model training, or production AI services often find on-premises deployment 40-60% cheaper over three years. The break-even point varies based on specific cloud pricing, power costs, and utilization rates. A hybrid approach—owning baseline capacity while bursting to cloud for peaks—often provides the optimal balance.
4. What infrastructure requirements must I meet before deploying H100 GPUs?
Answer: Deploying H100 GPUs demands robust infrastructure across multiple dimensions. Power requirements are substantial: each H100 SXM draws up to 700W, meaning an 8-GPU server requires 5.6kW for GPUs alone, plus additional power for CPUs, memory, and cooling—typically 7-8kW total per server. Your data center must provide adequate PDU capacity with appropriate power distribution.
Cooling is equally critical. H100 servers generate significant heat, requiring either advanced air cooling with high-CFM airflow or direct liquid cooling solutions. Network infrastructure should support at least 100Gbps connectivity for multi-GPU training, with 400Gbps recommended for large-scale deployments. Storage systems must deliver high-throughput data access to prevent GPU starvation. Finally, ensure your facility has appropriate physical space, raised flooring for cabling, and environmental monitoring. Cyfuture AI provides complete infrastructure assessment and design services to ensure your facility meets all H100 deployment requirements.
5. Can H100 GPUs be used for inference, or are they only for training?
Answer: H100 GPUs excel at both training and inference workloads, though their design optimizes particularly for training efficiency. For inference, the H100's Transformer Engine, FP8 precision support, and massive memory bandwidth deliver exceptional performance, processing up to 30x more inference requests per second compared to A100 GPUs for large language models.
The Multi-Instance GPU (MIG) capability makes H100s particularly valuable for inference scenarios, allowing you to partition a single GPU into up to seven independent instances. This enables efficient multi-tenant inference serving or running multiple different models simultaneously. For high-throughput inference requirements—such as serving millions of daily LLM requests—H100s provide excellent performance-per-dollar despite their premium pricing. However, for inference-only workloads with lower throughput requirements, you might also consider NVIDIA L40S or A100 alternatives that offer better cost optimization. The choice depends on your specific throughput requirements, latency constraints, and model complexity.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.