




































































Were You Searching for How AI Lab as a Service Revolutionizes Your Infrastructure?
Here's the answer:
AI Lab as a Service (AI LabaaS) represents a transformative cloud-based infrastructure model that provides on-demand access to fully configured AI research and development environments. By integrating cutting-edge GPU clusters, scalable cloud platforms, and pre-optimized AI tools, AI Lab as a Service eliminates infrastructure bottlenecks while enabling organizations to train, test, and deploy machine learning models at unprecedented speed and scale.
This comprehensive service architecture combines NVIDIA H100, A100, and L40S GPU clusters with Kubernetes-native environments, managed software services, and advanced networking infrastructure—delivering a complete AI acceleration platform that reduces time-to-market by 5x compared to traditional on-premises setups.
The numbers speak for themselves:
Here's what makes this shift inevitable:
According to Stanford's AI Index 2024, over 90% of academic and commercial AI projects cite infrastructure limitations as their top obstacle. Meanwhile, global AI R&D investments have surpassed $200 billion, yet companies waste months provisioning hardware and configuring environments.
That ends now.

What is AI Lab as a Service?
AI Lab as a Service is a cloud-native platform that virtualizes the entire AI research and development infrastructure. Unlike traditional on-premises labs requiring substantial capital investment, AI LabaaS delivers instant access to:
- High-performance GPU clusters (H100, H200, A100, L40S)
- Pre-configured AI frameworks (TensorFlow, PyTorch, CUDA)
- Scalable storage and networking optimized for AI workloads
- Managed services for deployment, monitoring, and optimization
- Collaborative tools enabling distributed team workflows
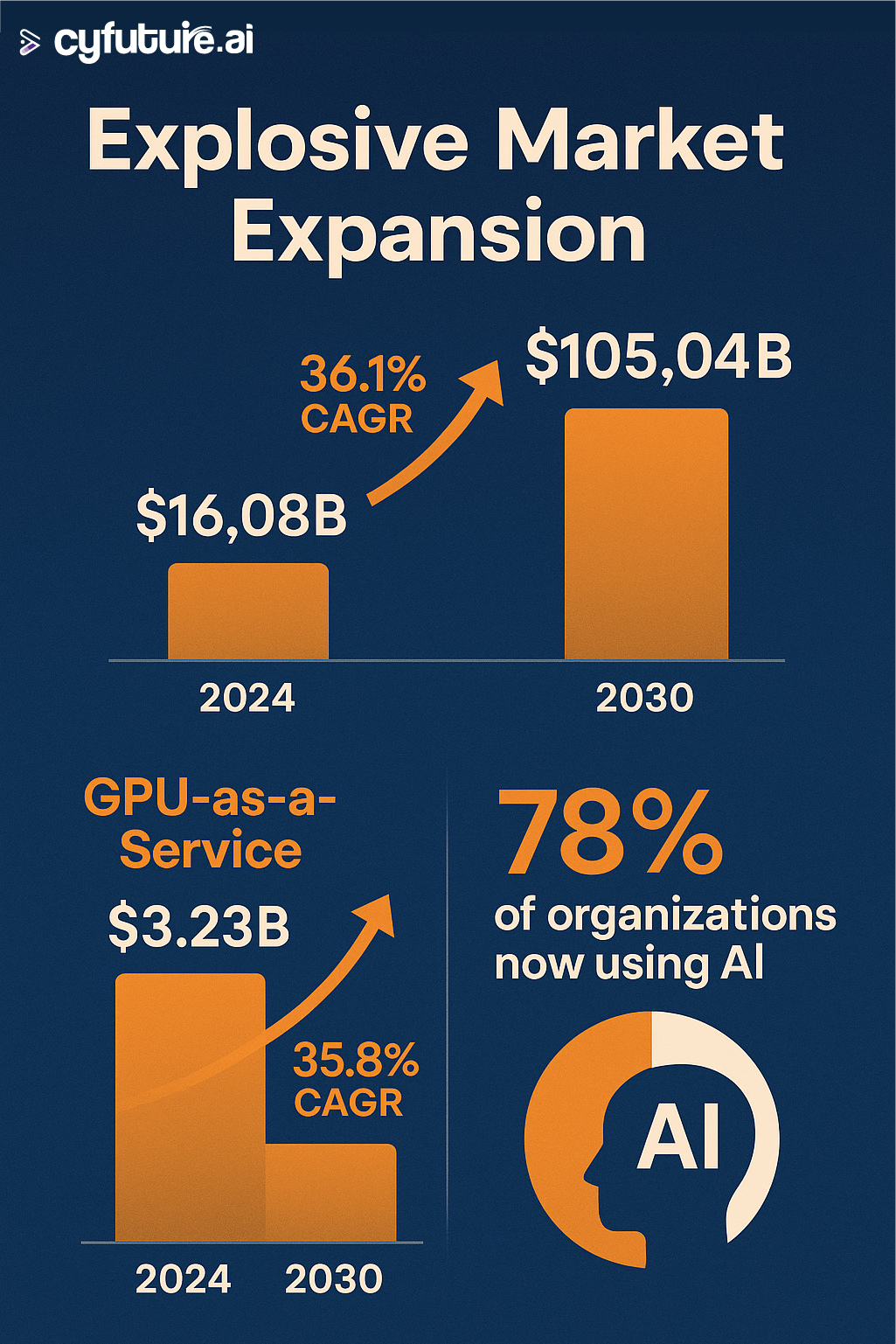
The global AI as a Service market reached $16.08 billion in 2024 and is projected to surge to $105.04 billion by 2030, exhibiting a robust CAGR of 36.1%. This explosive growth reflects enterprise demand for flexible, scalable AI infrastructure without the burden of hardware ownership.
The Critical Integration: Cloud + GPU + AI Tools
The Convergence Revolution
AI Lab as a Service isn't just about renting GPUs. It's about seamless integration across three foundational pillars:
1. Cloud Infrastructure Layer
The backbone of AI LabaaS leverages hyperscale cloud platforms:
- AWS maintains 30% market share of global cloud infrastructure spending in Q4 2024
- Microsoft Azure and Google Cloud provide comprehensive AI-native services
- Multi-cloud strategies enable 78% of enterprises to optimize workload placement
Cloud deployment offers immediate advantages:
- 271% ROI within three years when migrating to cloud-based AI infrastructure
- Payback periods under 6 months for cloud integration platforms
- Infrastructure cost savings averaging $152,000 annually
2. GPU Compute Power
The GPU as a Service market exploded from $3.23 billion in 2023 to a projected $49.84 billion by 2032, reflecting a CAGR of 35.8%. Here's why:
Modern AI workloads demand parallel processing capabilities that only GPUs can deliver:
- NVIDIA H100 GPUs provide 32 petaFLOPS of compute power for training large language models
- L40S GPUs balance AI performance with professional graphics rendering
- A100 GPUs dominate training workloads with 80GB HBM2e memory
Organizations using GPU cloud services report:
- Training speeds 9x faster compared to traditional infrastructure
- Cost reductions of 60-75% versus on-premises GPU investments
- Deployment times reduced from weeks to minutes
3. AI Tools and Frameworks
The third pillar integrates production-ready AI development tools:
- Pre-trained models from Hugging Face, OpenAI, and Meta
- MLOps platforms for model versioning and deployment
- Data processing pipelines with automated labeling and augmentation
- Monitoring dashboards with real-time performance metrics
In 2024, 78% of organizations reported using AI in at least one business function, up from 55% in 2023. The adoption of generative AI specifically jumped from 33% to 71% in the same period.
How Integration Delivers Unprecedented Value
Seamless Workflow Architecture
Here's how the three components work together:
Step 1: Cloud Provisioning
- Organizations access AI LabaaS through web consoles or APIs
- Cloud platforms automatically provision dedicated GPU instances
- Kubernetes orchestration manages multi-node clusters
Step 2: GPU Allocation
- Smart workload scheduling matches requirements with optimal GPU configurations
- Auto-scaling adjusts resources based on training demands
- Multi-Instance GPU (MIG) technology maximizes utilization
Step 3: Tool Integration
- Pre-configured environments include TensorFlow, PyTorch, and specialized libraries
- APIs connect to data lakes and object storage
- CI/CD pipelines enable continuous model deployment
Real Performance Metrics
Organizations leveraging integrated AI Lab as a Service report transformative results:
Speed Improvements:
- Model training cycles reduced by 80-90%
- Inference latency decreased to sub-100ms for real-time applications
- Development-to-production timelines shortened from months to weeks
Cost Optimization:
- Infrastructure costs reduced by 60-70% versus owned hardware
- Pay-per-use models eliminate idle resource waste
- Spot instances offer 50-90% savings for fault-tolerant workloads
Scalability Benefits:
- Instant scaling from single GPU to thousands of instances
- Geographic distribution ensures <10ms latency globally
- 99.9% uptime SLAs guarantee production reliability
Industry Applications: From Lab to Production
Healthcare Innovation
AI Lab as a Service enables healthcare organizations to:
- Process vast medical imaging datasets for diagnostics
- Train personalized treatment recommendation engines
- Accelerate drug discovery through molecular simulation
Example: Healthcare institutions using GPU-accelerated AI platforms report 30-40% improvements in case resolution rates.
Financial Services Transformation
Banks and financial institutions leverage integrated AI labs for:
- Real-time fraud detection analyzing millions of transactions
- Risk assessment models processing petabytes of historical data
- Algorithmic trading systems requiring ultra-low latency
The financial services sector invested $31.3 billion in AI in 2024, demonstrating massive commitment to AI infrastructure.
Manufacturing and Industrial AI
Manufacturers deploy AI LabaaS for:
- Predictive maintenance reducing downtime by 15-20%
- Quality control through computer vision inspection
- Digital twin simulations in NVIDIA Omniverse environments
Retail and E-commerce
Retailers harness integrated AI labs to power:
- Personalized recommendation engines
- Dynamic pricing optimization
- Inventory forecasting and supply chain analytics
Netflix case study: In 2024, 87% of Netflix's content decisions were driven by AI-powered data analytics, showcasing AI's transformative impact on business operations.
Key Technologies Enabling Integration
Cloud-Native Architecture
Modern AI Lab as a Service platforms leverage:
Containerization:
- Docker and Kubernetes for portable, scalable deployments
- Microservices architecture enabling modular functionality
- Service mesh for secure inter-service communication
Serverless Computing:
- Pay-per-execution pricing for inference workloads
- Automatic scaling from zero to thousands of requests
- No infrastructure management overhead
Edge Integration:
- Distributed inference for low-latency applications
- Federated learning across edge devices
- Hybrid cloud-edge architectures
GPU Orchestration Technologies
NVLink and NVSwitch:
- High-bandwidth GPU-to-GPU communication
- Enables training of models exceeding single GPU memory
- Critical for multi-node distributed training
Multi-Instance GPU (MIG):
- Partitions single GPUs into multiple isolated instances
- Maximizes utilization across diverse workloads
- Reduces cost per inference operation
CUDA and Tensor Cores:
- Specialized hardware for AI matrix operations
- 4-8x faster inference with TensorRT-LLM optimization
- Mixed-precision training for efficiency gains
AI Framework Integration
Open-Source Ecosystems:
- TensorFlow 2.x with Keras API for rapid prototyping
- PyTorch with dynamic computational graphs
- JAX for high-performance numerical computing
Model Serving Infrastructure:
- TensorFlow Serving and TorchServe for production deployment
- NVIDIA Triton Inference Server for multi-framework support
- Ray Serve for scalable Python-based serving
MLOps Platforms:
- Kubeflow for Kubernetes-native ML workflows
- MLflow for experiment tracking and model registry
- DVC for data and model versioning
Overcoming Common Challenges
Data Privacy and Security
Challenge: Sensitive data must remain protected in cloud environments.
Solution:
- Deploy in private cloud regions with dedicated hardware
- Implement encryption at rest and in transit
- Use confidential computing for processing sensitive data
Skills Gap
Challenge: Teams lack expertise in cloud-native AI infrastructure.
Solution:
- Partner with providers offering 24/7 expert support
- Leverage managed services to abstract complexity
- Invest in training and certification programs
According to the Pistoia Alliance 2025 survey, 34% of organizations cite lack of people as a barrier to AI adoption, up from 23% in 2024. Skills shortage represents a critical challenge.
Integration Complexity
Challenge: Existing tools and workflows must integrate with new infrastructure.
Solution:
- Use OpenAI-compatible APIs for seamless migration
- Implement data integration platforms (iPaaS)
- Adopt cloud-agnostic tools and frameworks
Future Trends: What's Next for AI Lab as a Service
Agentic AI Integration
By 2025, AI agents will become standard components of AI LabaaS platforms:
- Autonomous code generation for model development
- Self-optimizing hyperparameter tuning
- Intelligent workload scheduling across clusters
Quantum-AI Convergence
Quantum computing will begin integrating with AI workflows:
- Quantum-AI systems generating massive high-fidelity datasets
- Breakthroughs in material design and climate modeling
- Hybrid classical-quantum training algorithms
Sustainable AI Infrastructure
Energy efficiency will become paramount:
- Liquid cooling enabling rack densities above 120 kW
- Energy-aware training optimizing for carbon footprint
- Green data centers powered by renewable energy
The data center GPU market is projected to reach $192.68 billion by 2034, with sustainability becoming a key differentiator.
Sovereign AI Clouds
Nations will build localized AI infrastructure:
- By 2027, sovereign AI models will launch in at least 25 countries
- Regulations requiring data and compute residency
- Regional AI clouds supporting local languages and compliance

Accelerate Your AI Journey with Cyfuture AI
The convergence of cloud infrastructure, GPU compute power, and advanced AI tools has created an unprecedented opportunity for organizations to innovate at scale. AI Lab as a Service eliminates the traditional barriers of capital investment, infrastructure complexity, and lengthy procurement cycles.
The data is clear:
- Market growing from $16.08 billion (2024) to $105.04 billion (2030)
- Organizations achieving 271% ROI within three years
- 78% of enterprises now using AI in business functions
- 60-75% cost reduction versus on-premises infrastructure
"AI isn't replacing humans. It's replacing institutions. The next great entrepreneurs won't build apps — they'll build AIs that build apps." — Reid Hoffman, Co-founder, LinkedIn
Cyfuture AI stands at the forefront of this revolution, delivering:
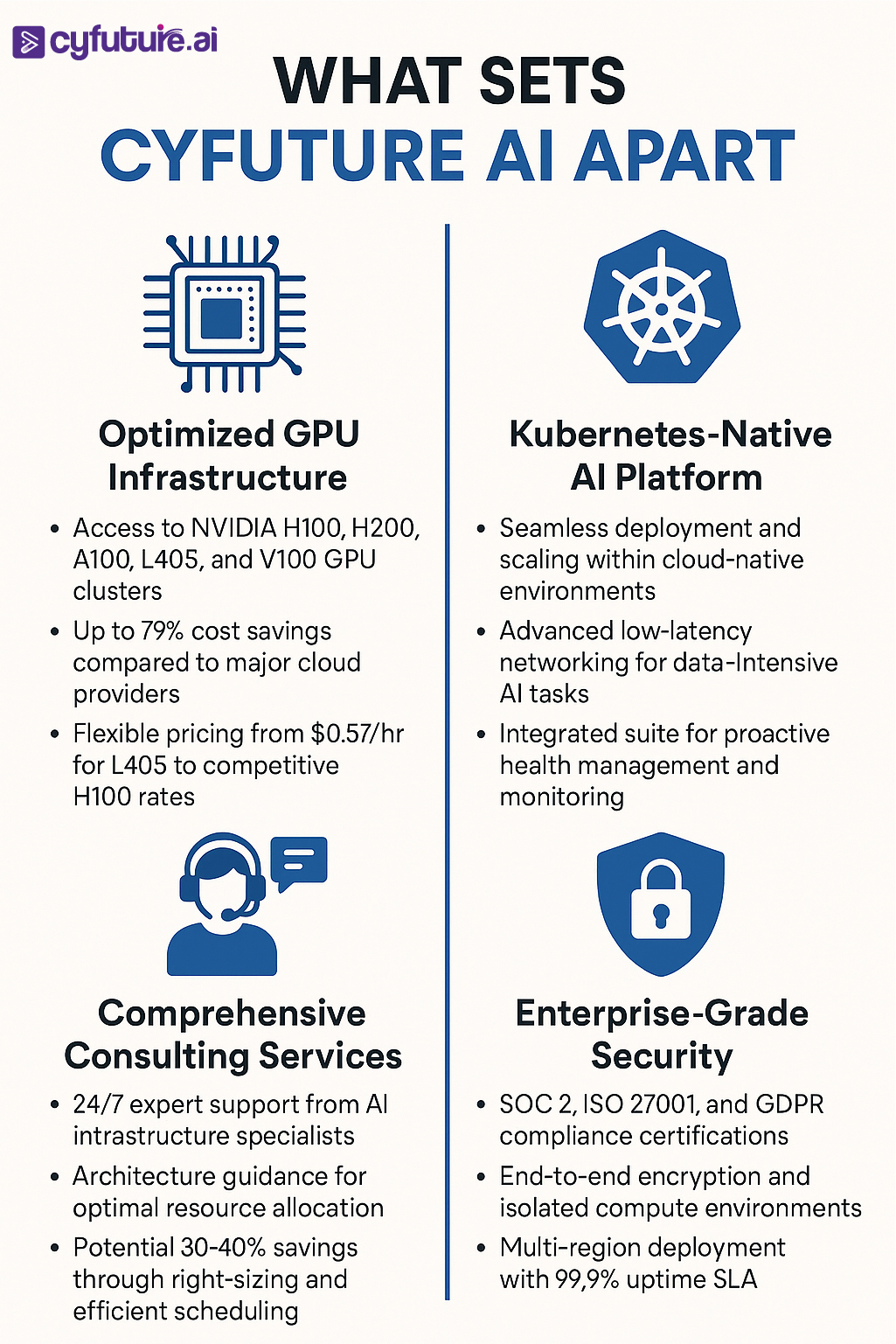
- Industry-leading GPU infrastructure with up to 73% cost savings
- Comprehensive AI platform with Kubernetes-native deployment
- 24/7 expert support from specialized AI infrastructure teams
- Enterprise-grade security with complete compliance certifications
Don't let infrastructure constraints limit your AI ambitions. The organizations that move fastest to adopt integrated AI Lab as a Service will capture disproportionate competitive advantage in their markets.
The question isn't whether to adopt AI Lab as a Service—it's how quickly you can implement it to stay ahead of competitors already leveraging these capabilities.
Transform your AI infrastructure with Cyfuture AI today.
Frequently Asked Questions (FAQs)
1. What is AI Lab as a Service and how does it differ from traditional AI infrastructure?
AI Lab as a Service (AI LabaaS) is a cloud-based platform providing on-demand access to complete AI research and development environments. Unlike traditional infrastructure requiring capital investment in hardware, facility management, and maintenance, AI LabaaS offers pay-as-you-go access to GPU clusters, pre-configured AI frameworks, and managed services. This model reduces costs by 60-70%, eliminates procurement delays, and enables instant scaling from single GPUs to thousands of instances.
2. How much does AI Lab as a Service cost compared to on-premises infrastructure?
Organizations typically achieve 60-75% cost reduction with AI LabaaS versus on-premises setups. For example, Cyfuture AI offers competitive GPU pricing starting at $0.57/hr for L40S and $2.34/hr for H100 GPUs, representing up to 73% savings versus major cloud providers. When factoring in eliminated hardware depreciation, facility costs, and maintenance, enterprises report 271% ROI within three years with payback periods under 6 months.
3. Which GPUs should I choose for different AI workloads?
For large language model training (70B+ parameters): NVIDIA H100 or H200 GPUs with their superior memory bandwidth and Transformer Engine support.
For balanced AI and graphics workloads: L40S GPUs offering 48GB GDDR6 with excellent AI performance and professional visualization capabilities.
For cost-effective training of smaller models (7B-13B parameters): A100 GPUs (40GB/80GB) provide optimal price-performance.
For inference and edge deployment: T4 GPUs deliver excellent performance-per-watt for cost-effective production serving.
4. How secure is AI Lab as a Service for sensitive data and proprietary models?
Enterprise-grade AI LabaaS platforms implement comprehensive security measures including SOC 2, ISO 27001, and GDPR compliance certifications. Security features include end-to-end encryption, isolated compute environments, private cloud deployment options, confidential computing for processing sensitive data, and role-based access control. Organizations handling highly sensitive data can opt for dedicated hardware instances or private cloud regions ensuring complete isolation.
5. Can AI Lab as a Service integrate with my existing tools and workflows?
Modern AI LabaaS platforms provide extensive integration capabilities through standard APIs, Kubernetes-native deployments, and support for popular frameworks. They offer OpenAI-compatible APIs for seamless migration from other platforms, integration with CI/CD pipelines (Jenkins, GitLab, GitHub Actions), connectivity to data lakes and object storage, and compatibility with MLOps tools like MLflow, Kubeflow, and Weights & Biases. Most platforms also provide pre-built connectors for common enterprise systems.
6. What level of support can I expect from AI Lab as a Service providers?
Leading providers like Cyfuture AI offer 24/7 expert support from AI infrastructure specialists, including architecture guidance for optimal resource allocation, performance optimization and troubleshooting, workload migration assistance from on-premises or other clouds, training on cloud-native AI tools and best practices, and dedicated account management for enterprise customers. Many providers report response times under 15 minutes for critical issues.
7. How quickly can I get started with AI Lab as a Service?
AI LabaaS enables rapid onboarding with most platforms offering instant provisioning through web consoles or APIs. Organizations can access GPU instances within minutes, leverage pre-configured environments with popular frameworks, and scale from development to production seamlessly. Typical timelines include same-day access for standard configurations, 1-3 days for customized enterprise deployments, and 1-2 weeks for complete migration of existing workloads including team training.
8. What are the key metrics to track when using AI Lab as a Service?
Organizations should monitor GPU utilization rates (target 70-85%), training job completion times and throughput, inference latency and requests per second, cost per training run and per inference, model accuracy and performance metrics, infrastructure uptime and availability, and total cost of ownership versus on-premises baseline. Most platforms provide integrated dashboards for real-time monitoring of these KPIs.
9. How does AI Lab as a Service support team collaboration and remote work?
Cloud-based AI labs enable distributed team collaboration through shared workspaces and notebooks (Jupyter, Google Colab), version-controlled model and code repositories, role-based access to datasets and computing resources, real-time experiment tracking and comparison, and secure remote access from anywhere with internet connectivity. This infrastructure proved critical during the shift to remote work, with 78% of organizations now supporting distributed AI teams.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.