




































































Introduction — From AI Hype to Business Reality
The last few years have been a whirlwind for Artificial Intelligence. ChatGPT, Gemini, and Claude have shown the world what’s possible when machines can generate human-like responses.
But for many enterprises, the results have been mixed. Generative AI pilots often hit walls of inaccuracy, hallucinations, and compliance risk.
That’s where Retrieval-Augmented Generation (RAG) steps in—a framework designed to bridge the gap between general-purpose intelligence and business-grounded accuracy.
In essence, RAG gives your AI model access to your organization’s trusted knowledge base, letting it answer with facts, citations, and confidence.
This blog breaks down how RAG works, why it matters for businesses, and how you can deploy it effectively using modern AI infrastructure like GPU clusters, serverless inference, and cloud-native pipelines.
What Is Retrieval-Augmented Generation (RAG)?
RAG is an AI architecture that enhances large language models (LLMs) by augmenting them with external, domain-specific data during inference.
Instead of relying purely on what a model already knows, RAG enables it to retrieve relevant, up-to-date information before generating a response.
Think of it this way:
Traditional LLMs are like students answering questions from memory. RAG-enabled systems are like students who can check their textbooks and notes before responding.
How It Works — A Simple Flow
- User query is received.
- Retriever searches for relevant data from your company’s knowledge base, vector database, or document repository.
- Generator (an LLM) combines that context with the query to produce a grounded, accurate answer.
- Response includes citations or links to the retrieved sources.
The result? Accurate, contextual, and auditable AI output.
The Core RAG Pipeline
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Pro Insight:
Unlike fine-tuning—which permanently alters model weights—RAG allows you to keep models frozen and simply update your knowledge base whenever data changes.
Why Businesses Are Adopting RAG
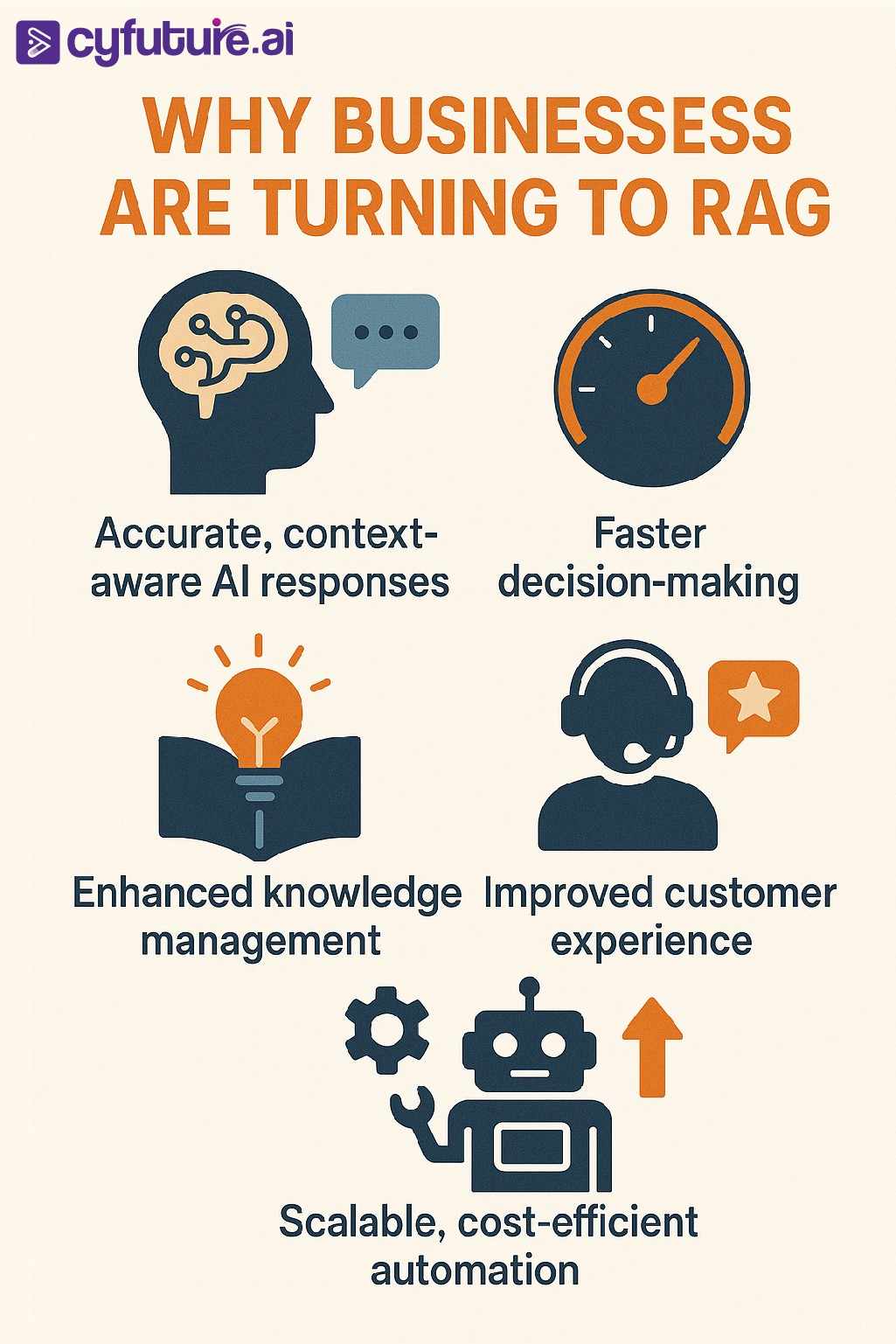
1. Accuracy and Trust
Hallucinations are AI’s biggest credibility killer. RAG grounds your AI’s responses in verified sources, making them traceable and compliant with industry standards (e.g., ISO, GDPR).
2. Faster Knowledge Updates
In industries like finance, healthcare, and SaaS, new information changes daily. With RAG, you can index fresh data overnight and immediately improve your AI’s knowledge—no retraining needed.
3. Cost Efficiency
Fine-tuning large LLMs can cost thousands in GPU time. A RAG pipeline lets you keep smaller models while improving accuracy through smart retrieval—especially powerful when combined with serverless inferencing.
4. Business Agility
Teams can experiment rapidly with new datasets, domains, or languages. Deployments are modular—update embeddings or swap databases without touching your base model.
5. Competitive Advantage
Businesses using RAG are already building smarter chatbots, voicebots, document copilots, and data assistants that deliver fact-based insights in real time.
Top Enterprise Use Cases for RAG
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Example:
A telecom firm built a RAG voicebot integrated with its ticketing database. Field engineers can now ask, “How do I reset router type XR240?” and receive an instant spoken answer sourced directly from manuals—no hallucinations, no guesswork.

Scaling RAG: GPU Clusters vs Serverless Inferencing
GPU Clusters
- Ideal for high-volume, low-latency workloads like real-time chat or voice applications.
- Offer massive throughput but come with high upfront cost and maintenance overhead.
- Best suited for enterprises running persistent workloads and custom fine-tuned models.
Serverless Inferencing
- Ideal for dynamic or bursty workloads (e.g., customer queries that spike during business hours).
- Pay only when models are invoked—perfect for scaling without idle GPU costs.
- Downside: potential cold-start latency unless mitigated via warm pools or caching.
Hybrid Strategy
Modern enterprises increasingly use hybrid RAG pipelines—combining GPU clusters for retrieval-heavy, latency-critical tasks and serverless endpoints for generation bursts.
Example Architecture:
- Retrieval → CPU / GPU vector DB node
- Generation → Serverless LLM endpoint
- Monitoring → Cloud-native observability + caching layer
This hybrid design optimizes both speed and cost, ensuring reliable enterprise-scale deployment.
RAG in Conversational AI: Chatbots and Voicebots
RAG has supercharged conversational interfaces. Instead of generic or scripted bots, businesses now deploy RAG-powered assistants that can search, understand, and respond using real internal data.
RAG Chatbots
- Pull answers from knowledge bases and CRM systems.
- Provide source links and confidence scores.
- Continuously learn as new data is added.
RAG Voicebots
- Combine speech-to-text (STT) + retrieval + text-to-speech (TTS).
- Ideal for hands-free scenarios: customer service, technical field support, logistics.
- When paired with GPU acceleration, latency can drop below 400ms per query.
Why It Matters:
RAG turns voice and chat agents from reactive responders into proactive assistants—trustworthy, explainable, and aligned with brand voice.
Building an Enterprise-Ready RAG Pipeline
To move from prototype to production:
- Define business objectives. What problem should your RAG solution solve—support, research, compliance, etc.?
- Collect and clean data. Remove duplicates, irrelevant content, and outdated information.
- Choose the right vector database. Evaluate latency, scale, and security (e.g., Pinecone for SaaS, FAISS for on-prem).
- Set up embedding + retrieval. Optimize chunk size and retrieval strategies for speed.
- Integrate with orchestration tools. Use frameworks like LangChain, LlamaIndex, or DSPy to handle context flow.
- Deploy & monitor. Track latency, relevance, hallucination rate, and retrieval coverage.
- Iterate continuously. Add more data sources, tune retrievers, and introduce caching.
Best Practice:
Version your knowledge base—every update should be trackable and reversible to ensure governance and trust.
Challenges & How to Overcome Them
1. Data Quality
RAG’s performance depends on clean, relevant data.
Solution: Set up automated ETL pipelines and run semantic deduplication to ensure accuracy.
2. Latency
Retrieval and generation steps can add delay.
Solution: Pre-compute frequent queries, use caching layers, and tune retrieval chunk sizes.
3. Cost Management
Large GPU clusters can be expensive.
Solution: Offload intermittent workloads to serverless inference platforms like AWS SageMaker or GCP Vertex AI.
4. Security & Compliance
Sensitive data must be protected throughout ingestion, storage, and retrieval.
Solution: Use encrypted vector stores, role-based access control (RBAC), and PII masking.
5. Explainability
Users want to know where answers come from.
Solution: Always include citations or hyperlinks to retrieved documents in the AI’s responses.

The Future of RAG in Business AI
RAG is rapidly evolving beyond text retrieval.
Next-generation systems are integrating multimodal retrieval—combining documents, images, and audio to provide richer context for AI models.
We’re also seeing RAG merge with agentic AI, where autonomous agents use RAG to continuously search, reason, and act.
In the next 3–5 years, expect:
- Multimodal RAG pipelines: integrating visual and audio data.
- Automated data freshness checks via AI pipelines.
- Voice-native RAG copilots for field and frontline workers.
- Industry-specific RAG frameworks for healthcare, legal, and fintech compliance.
The businesses that start building RAG maturity today will own the trust layer of tomorrow’s AI economy.
Conclusion — Grounded AI Is the Future
Retrieval-Augmented Generation marks a turning point in the evolution of enterprise AI.
It shifts the narrative from “smart models” to “trusted systems” — ones that know where their answers come from.
By combining retrieval precision with generative creativity, RAG offers enterprises a sustainable way to scale AI without sacrificing trust, compliance, or cost control.
As AI pipelines mature and infrastructure becomes more efficient—through GPU clusters, serverless inferencing, and hybrid deployment—RAG will form the foundation for every reliable business assistant, chatbot, and voicebot.
The future of AI in business isn’t just generative—it’s retrieval-augmented, explainable, and grounded in truth.
FAQs:
1. What is Retrieval-Augmented Generation (RAG)?
RAG is an AI framework that combines document retrieval with generative AI. It retrieves relevant information from external data sources before generating responses, resulting in more accurate and context-aware outputs.
2. How does RAG improve business AI performance?
RAG enhances the quality and reliability of AI-generated content by grounding it in verified data. This helps businesses deliver factual, personalized, and up-to-date information across customer support, marketing, and analytics.
3. What are the main advantages of using RAG models?
RAG models improve accuracy, reduce hallucinations, and make large language models more explainable. They also allow real-time updates without retraining the entire model.
4. How can businesses implement RAG in their workflows?
Businesses can integrate RAG using vector databases, APIs, and inference frameworks. It’s especially useful for knowledge management, customer interaction, and document summarization systems.
5. What role does serverless inferencing play in RAG systems?
Serverless inferencing allows RAG models to scale dynamically based on workload. This reduces infrastructure costs and ensures fast, efficient retrieval and generation for enterprise applications.
Author Bio:
Tarandeep is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. He excels at breaking down complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Tarandeep is passionate about helping readers stay informed and leverage the latest digital innovations effectively.