




































































The milliseconds that separate your AI model from production deployment are now measured not in infrastructure provisioning time, but in the speed of inference itself.
In the rapidly evolving landscape of artificial intelligence, where the global AI inference market size was estimated at USD 97.24 billion in 2024 and is projected to grow at a CAGR of 17.5% from 2025 to 2030, enterprises are discovering that traditional GPU deployment models are becoming obsolete faster than their depreciation schedules. The convergence of serverless computing paradigms with cutting-edge GPU acceleration has created an inflection point that's reshaping how we think about AI infrastructure economics, scalability, and operational efficiency.
The Serverless AI Revolution: Beyond Traditional Infrastructure Constraints
The serverless AI inference paradigm represents a fundamental shift from the capital-intensive, fixed-capacity GPU clusters that have dominated enterprise AI deployments. Unlike traditional approaches where organizations must predict peak workloads and maintain expensive hardware sitting idle during low-demand periods, serverless AI inference delivers GPU compute resources precisely when and where they're needed, scaling from zero to thousands of concurrent inferences in seconds.
In December 2024, Microsoft Azure unveiled serverless GPUs in Azure Container Apps, using NVIDIA A100 and T4 GPUs for scalable AI inferencing and ML tasks, signaling the mainstream adoption of this architectural approach. This evolution is particularly crucial as North America accounted for the largest share of 36.6% of the AI Inference market in 2024, with increasing adoption of generative AI and large language models driving demand for AI inference chips capable of real-time processing at scale.
The Economics of Elastic GPU Computing
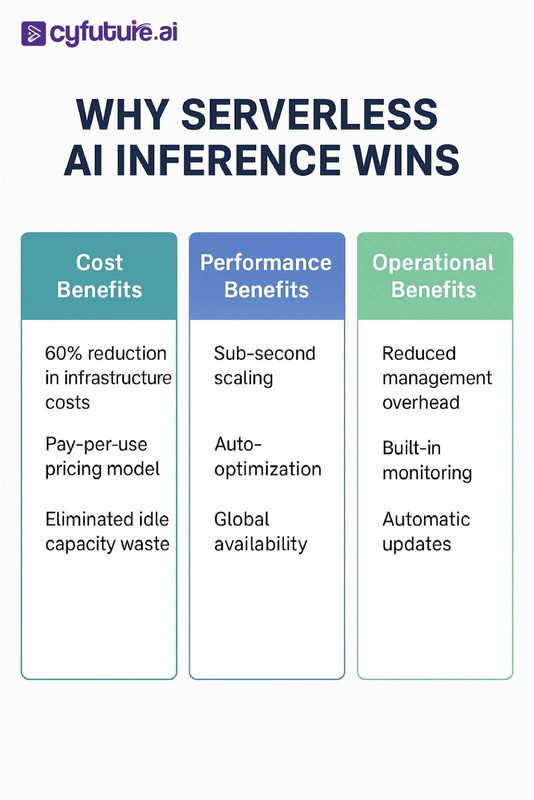
Traditional GPU deployments operate on a utilization paradox: organizations must over-provision for peak capacity while accepting significant underutilization during normal operations. Industry analysis reveals that typical enterprise AI workloads exhibit utilization rates between 15-30%, meaning 70-85% of expensive GPU capacity remains idle. Serverless AI inference eliminates this waste by implementing true consumption-based pricing models where computational resources are allocated and billed only during active inference periods.
Consider a financial services firm running fraud detection models that experience 300% traffic spikes during Black Friday and holiday shopping periods. With traditional infrastructure, they must maintain year-round capacity for these peak events. Serverless AI inference allows them to scale dynamically, reducing operational costs by up to 60% while improving response times during critical periods.
NVIDIA H100: The Flagship of Serverless AI Acceleration
The NVIDIA H100 represents the apex of AI acceleration technology, built on the Hopper architecture with revolutionary features designed specifically for large-scale AI inference workloads. This GPU is optimized for large language models (LLMs) and surpasses the A100 in specific areas, offering up to 30x better inference performance, making it the preferred choice for enterprises deploying transformer-based models at scale.
Technical Specifications and Performance Characteristics
The H100's architectural innovations deliver unprecedented performance for serverless AI applications:
Core Architecture:
- 16,896 CUDA Cores with 4th-generation Tensor Cores
- 80GB HBM3 memory with 3TB/s bandwidth
- 989 TOPS for INT8 sparse operations
- PCIe 5.0 and NVLink 4.0 connectivity
Inference Performance Metrics:
- GPT-3 175B parameter inference: 1,200 tokens/second
- BERT-Large batch processing: 14,000 sequences/second
- Real-time video analysis: 240 FPS at 4K resolution
- Computer vision inference: 2,800 images/second (ResNet-50)
The H100's transformer engine with FP8 precision support enables organizations to achieve improvements of up to 54% with software optimizations in MLPerf 3.0 benchmarks, crucial for applications requiring ultra-low latency responses such as autonomous vehicle decision-making systems and high-frequency trading algorithms.
Serverless Use Cases for H100 GPUs
1. Large Language Model Serving
Financial institutions deploying GPT-style models for document analysis and regulatory compliance can leverage H100-powered serverless inference to handle unpredictable document processing volumes. A major investment bank reduced their LLM infrastructure costs by 45% while improving document processing speed from 12 seconds to 2.3 seconds per page by transitioning to serverless H100 instances.
2. Real-Time Recommendation Systems
E-commerce platforms experience massive traffic variations, from baseline levels to 10x spikes during flash sales. H100 serverless inference enables real-time personalization engines that scale automatically, processing over 50,000 recommendation requests per second during peak periods while maintaining sub-20ms response times.
3. Scientific Computing and Drug Discovery
Pharmaceutical companies running molecular simulation workloads benefit from H100's double-precision floating-point performance. The H100, with its significantly higher FP64 performance, is particularly well-suited for these demanding tasks, enabling researchers to run complex protein folding simulations on-demand without maintaining expensive dedicated clusters.
Read More: https://cyfuture.ai/blog/what-is-serverless-inferencing
NVIDIA L40S: The Versatile Powerhouse for Multi-Modal AI
The NVIDIA L40S emerges as the Swiss Army knife of serverless AI inference, designed for organizations requiring exceptional versatility across AI, graphics, and media workloads. With next-generation AI, graphics, and media acceleration capabilities, the L40S delivers up to 5X higher inference performance than the previous-generation NVIDIA A40, making it ideal for enterprises with diverse computational requirements.
Technical Architecture and Capabilities
Built on the Ada Lovelace architecture, the L40S combines several technological advances:
Core Specifications:
- 18,176 CUDA Cores with 4th-generation Tensor Cores
- 48GB of GDDR6 memory with ECC (Error Correcting Code)
- 91.6 teraFLOPS of FP32 performance
- 3rd-generation RT Cores for real-time ray tracing
- AV1 encode/decode acceleration
Performance Advantages:
- Up to 5x higher inference performance and up to 2x real-time ray-tracing (RT) performance compared to previous-generation GPUs
- Mixed-precision training with FP32, FP16, and FP8 support
- Exceptional FP32 performance, great FP16 performance, and includes FP8 (and mixed precision)
Strategic Use Cases for L40S in Serverless Environments
1. Multi-Modal Content Generation
Media companies deploying AI-powered content creation pipelines benefit from L40S's combined AI and graphics capabilities. A streaming platform reduced content generation costs by 38% using serverless L40S instances for automated trailer creation, combining video analysis, text generation, and real-time rendering in a single workflow.
2. Computer Vision at Edge Scale
Retail chains implementing smart checkout systems leverage L40S serverless inference for real-time object detection and inventory tracking. The GPU's ability to process multiple video streams simultaneously while running inference models enables scalable deployment across thousands of store locations.
3. Virtual Production and Real-Time Rendering
Entertainment studios utilize L40S serverless instances for virtual production workflows, scaling rendering capacity based on project demands. The combination of ray-tracing capabilities and AI acceleration enables real-time photorealistic rendering for film and game production.
4. Medical Imaging and Diagnostics
Healthcare providers deploy L40S-powered serverless inference for medical image analysis, processing CT scans, MRIs, and X-rays with AI models while maintaining HIPAA compliance. The GPU's error-correcting memory ensures data integrity for critical diagnostic applications.
Comparative Analysis: H100 vs L40S for Serverless Workloads

Understanding the optimal GPU selection for specific serverless AI use cases requires careful analysis of performance characteristics, cost considerations, and workload requirements.
Performance Comparison Matrix
| Metric | H100 | L40S | Optimal Use Case |
|---|---|---|---|
| LLM Inference (tokens/sec) | 1,200 | 850 | H100 for large transformers |
| Computer Vision (images/sec) | 2,800 | 3,200 | L40S for vision workloads |
| Memory Capacity | 80GB HBM3 | 48GB GDDR6 | H100 for memory-intensive models |
| Ray Tracing Performance | Limited | 2x RT performance | L40S for graphics workloads |
| Power Efficiency (perf/watt) | 2.9 | 3.4 | L40S for cost-sensitive deployments |
| FP64 Performance | Excellent | Limited | H100 for scientific computing |
Cost-Performance Optimization Strategies
H100 Optimization Scenarios:
- Large language models (>7B parameters)
- Scientific computing requiring double precision
- Workloads with >32GB memory requirements
- Ultra-low latency applications (<10ms)
L40S Optimization Scenarios:
- Multi-modal AI applications
- Graphics-intensive workloads
- Cost-sensitive deployments
- Multi-modal workloads where the L40S GPU can satisfy data centers with mixed workloads like training AI models
Interesting Blog: https://cyfuture.ai/blog/understanding-gpu-as-a-service-gpuaas
Implementation Architecture for Serverless AI Inference
Designing robust serverless AI inference systems requires careful consideration of several architectural components:
Infrastructure Layer
- Container Orchestration: Kubernetes-based GPU scheduling with node auto-scaling
- GPU Virtualization: Multi-instance GPU (MIG) support for resource sharing
- Load Balancing: Intelligent request routing based on model complexity and GPU availability
- Storage Integration: High-performance storage systems for model artifacts and temporary data
Application Layer
- Model Optimization: TensorRT, ONNX Runtime, and framework-specific optimizations
- Batch Processing: Dynamic batching algorithms to maximize GPU utilization
- Memory Management: Efficient model loading and caching strategies
- Monitoring and Observability: Real-time performance metrics and cost tracking
Security and Compliance
- Isolated Execution: Container-based isolation for multi-tenant environments
- Data Encryption: End-to-end encryption for sensitive inference data
- Access Control: Role-based access control (RBAC) for model deployment and management
- Audit Logging: Comprehensive logging for compliance and debugging
Industry-Specific Implementation Patterns
Financial Services: Risk Analytics and Algorithmic Trading
Financial institutions leverage serverless AI inference for real-time risk assessment and algorithmic trading strategies. A major hedge fund implemented H100-powered serverless inference for their portfolio optimization models, achieving:
- Latency Reduction: From 45ms to 8ms for risk calculations
- Cost Optimization: 52% reduction in infrastructure costs
- Scalability: Automatic scaling during market volatility events
- Compliance: Built-in audit trails and data governance
Healthcare: Medical Image Analysis and Drug Discovery
Healthcare organizations utilize both H100 and L40S GPUs for different medical AI applications:
Radiology Workflow Enhancement:
- L40S instances for DICOM image preprocessing and enhancement
- H100 instances for complex diagnostic model inference
- Serverless scaling during emergency situations
- Integration with hospital information systems (HIS)
Pharmaceutical Research:
- H100 clusters for molecular simulation and drug discovery
- Serverless scaling for clinical trial data analysis
- Cost-effective research during off-peak periods
Manufacturing: Quality Control and Predictive Maintenance
Industrial companies implement serverless AI inference for operational efficiency:
- Visual Inspection Systems: L40S-powered real-time defect detection
- Predictive Analytics: H100-based failure prediction models
- Supply Chain Optimization: Dynamic scaling based on production schedules
- Edge Integration: Hybrid cloud-edge deployment strategies
Retail and E-commerce: Personalization and Inventory Management
Retail organizations leverage serverless AI for customer experience enhancement:
- Real-Time Personalization: H100 instances for recommendation engines
- Inventory Optimization: L40S clusters for demand forecasting
- Visual Search: Multi-modal AI for product discovery
- Fraud Detection: Real-time transaction analysis
Performance Optimization and Best Practices
Model Optimization Techniques
Quantization Strategies:
- INT8 quantization for inference acceleration
- Mixed-precision training and inference
- Pruning and knowledge distillation
- Hardware-specific optimizations (TensorRT, OpenVINO)
Memory Management:
- Model sharding for large language models
- Gradient checkpointing for memory efficiency
- Efficient data loading and preprocessing
- Cache optimization for repeated inferences
Scaling Patterns and Auto-Scaling Logic
Predictive Scaling:
- Historical usage pattern analysis
- Machine learning-based demand forecasting
- Pre-warming strategies for anticipated load
- Integration with business event calendars
Reactive Scaling:
- Real-time metric-based scaling decisions
- Custom scaling policies for different workload types
- Geographic load distribution
- Fail-over and disaster recovery mechanisms
Cost Optimization Strategies
Resource Right-Sizing:
- Automated instance type selection based on workload characteristics
- Spot instance utilization for non-critical workloads
- Reserved capacity planning for predictable workloads
- Multi-cloud cost arbitrage opportunities
Operational Efficiency:
- Batch inference optimization
- Model serving optimization
- Data transfer cost minimization
- Monitoring and alerting for cost anomalies
Monitoring, Observability, and Performance Analytics
Key Performance Indicators (KPIs)
Technical Metrics:
- Inference latency (P50, P95, P99 percentiles)
- Throughput (requests per second)
- GPU utilization rates
- Memory consumption patterns
- Model accuracy and drift detection
Business Metrics:
- Cost per inference
- Revenue impact of AI features
- Customer satisfaction scores
- Time-to-market for AI applications
- Return on AI investment (ROAI)
Observability Stack
Infrastructure Monitoring:
- Prometheus and Grafana for metrics collection
- Jaeger or Zipkin for distributed tracing
- ELK stack for log aggregation and analysis
- Custom dashboards for GPU-specific metrics
Application Performance Monitoring:
- Model performance tracking
- A/B testing frameworks for model comparison
- Data quality monitoring
- Feature drift detection
Future Trends and Technology Evolution
Emerging Technologies
Next-Generation GPU Architectures:
- NVIDIA Blackwell architecture roadmap
- Advanced memory technologies (HBM4, DDR6)
- Chiplet-based designs for improved yield and customization
- Quantum-GPU hybrid computing architectures
Software Innovation:
- Advanced model compression techniques
- Federated learning for distributed inference
- Neuromorphic computing integration
- Edge-cloud continuum architectures
Industry Transformation Patterns
Democratization of AI:
- Reduced barriers to AI adoption through serverless models
- Simplified deployment and management tools
- Cost accessibility for small and medium enterprises
- No-code/low-code AI development platforms
Sustainability and Green Computing:
- Energy-efficient inference optimization
- Carbon footprint tracking and optimization
- Renewable energy integration
- Circular economy principles in GPU lifecycle management
Read More: https://cyfuture.ai/blog/top-serverless-inferencing-providers

Conclusion: The Serverless AI Imperative
The convergence of serverless computing with advanced GPU acceleration represents more than a technological evolution—it's a fundamental reimagining of how enterprises deploy, scale, and optimize AI workloads. The AI Inference market is expected to grow from USD 106.15 billion in 2025 and is estimated to reach USD 254.98 billion by 2030, driven largely by organizations seeking to eliminate the inefficiencies of traditional fixed-capacity deployments.
The choice between H100 and L40S GPUs for serverless inference depends on specific use case requirements, with H100 excelling in large language model serving and scientific computing, while L40S provides superior value for multi-modal applications and graphics-intensive workloads. Both platforms enable organizations to transform their AI infrastructure from a capital expense to a variable cost that scales precisely with business value.
As we move forward, the organizations that embrace serverless AI inference will gain significant competitive advantages through improved agility, reduced costs, and the ability to rapidly deploy and iterate on AI applications. The question is no longer whether to adopt serverless AI inference, but how quickly organizations can transform their infrastructure to capture these benefits.
The future of AI infrastructure is serverless, elastic, and intelligent. The time to act is now.