




































































Introduction
Artificial Intelligence (AI) is no longer just a buzzword. It powers applications ranging from chatbots and predictive analytics to autonomous vehicles and fraud detection. But while training AI models gets much of the attention, the real challenge often lies in deployment and inference, making those trained models work reliably in the real world.
Traditionally, inference required dedicated servers or container clusters, leading to high costs, complex scaling, and wasted idle resources.
This is where serverless inferencing steps in. By combining serverless computing with AI, businesses can deploy models that scale automatically, run without dedicated infrastructure, and only incur costs when used.
This guide provides a deep dive into serverless inference, covering:
- What serverless inferencing is
- Why serverless is suited for AI/ML workloads
- Detailed step-by-step workflow
- Real-world use cases across industries
- Top 10 Platforms for Serverless Inferencing
- Best practices for optimization
- Future trends shaping AI serverless inference
By the end, you'll understand not only what serverless inferencing is, but also how to leverage it effectively for competitive advantage.
What is Serverless Inferencing?
Serverless inferencing is the process of deploying AI or ML models using serverless computing platforms. Unlike traditional setups, you do not manage servers because the cloud provider handles scaling, availability, and execution.
- Models run only when invoked.
- Compute resources are automatically provisioned.
- You pay only for execution time, not for idle capacity.
Example: A retailer deploying a recommendation model does not need to keep servers running all the time. Instead, the model executes only when a customer visits the app.
This shift enables businesses to move away from always on costly servers to on demand pay as you go AI deployments.
Serverless Inference Vs Traditional Deployment
| Feature | Traditional Servers (VMs) | Containers (Kubernetes) | Serverless Functions |
|---|---|---|---|
| Infrastructure | Fully managed by team | Managed by DevOps team | Fully managed by provider |
| Scaling | Manual or scripted | Semi-automatic | Fully automatic |
| Cost model | Fixed (idle costs) | Mixed | Pay-per-execution |
| Maintenance | High (patching, updates) | Moderate | None |
| Deployment speed | Slow | Medium | Fast |
| Best for | Heavy, constant workloads | Microservices, DevOps | On-demand inference |
Insight: Serverless inference is most effective for spiky, unpredictable workloads where usage varies dramatically (e.g., chatbots during peak hours, recommendation systems during sales).
Why Use Serverless for AI/ML Inference?
Scalability
Serverless platforms automatically scale functions to handle traffic surges. A model that serves 10 predictions per second can instantly scale to 10,000 predictions per second without manual intervention.
Cost Efficiency
No idle servers consuming resources. With serverless, you pay only when requests are made. This is especially valuable for applications with inconsistent or bursty workloads.
Faster Deployment
Deploying an ML model as a serverless function eliminates weeks of infrastructure setup. Developers can go from training → deployment → serving in hours.
Flexibility Across Frameworks
Supports TensorFlow, PyTorch, Hugging Face, Scikit-learn, and other ML libraries.
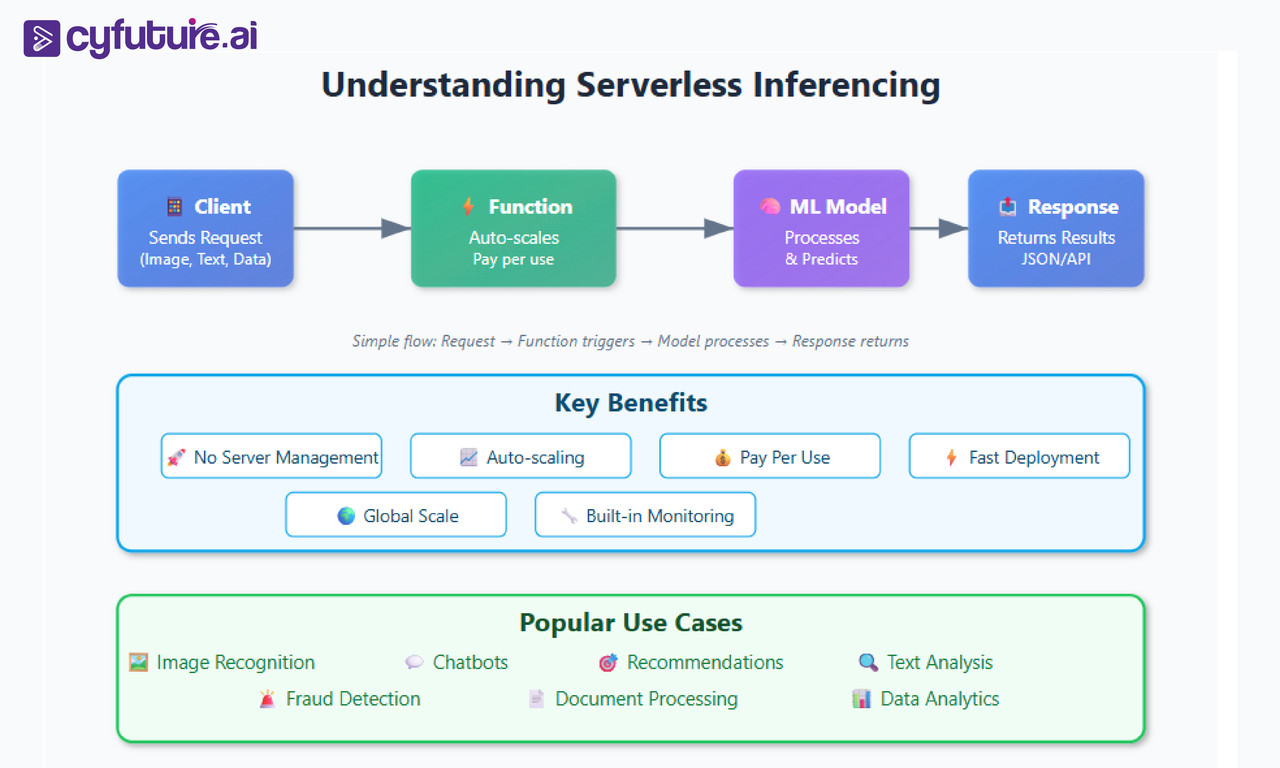
How Serverless Inference Works (Step by Step)
Serverless inferencing enables running AI and ML models for real-time predictions without the need to provision, configure, or manage servers. The infrastructure is fully managed by the cloud provider, allowing developers and organizations to focus solely on sending inference requests and integrating the results into their applications.

Here is a step-by-step explanation of how serverless inferencing works in modern AI workflows:
1. Model Deployment
- You upload your pre-trained machine learning model (e.g., a conversational LLM or vision model) to a cloud platform such as Cyfuture AI, AWS, or Hugging Face.
- You can use platform-provided containers for major frameworks (like TensorFlow, PyTorch) or bring your own; maximum container size limits may apply (e.g., 10GB on AWS SageMaker).
2. Serverless Endpoint Creation
- The platform creates a serverless endpoint for your model. You don't have to specify or maintain any underlying compute resources or scaling policies.
- The endpoint is ready to receive inference requests via a standard API (such as HTTP POST).
3. Inference Requests
- Applications, scripts, or end-users send HTTP requests to the endpoint, typically with:
- The name or slug of the model to use
- User input or prompt data (such as text, image, etc.)
- Optional parameters like temperature (controls randomness) and max_tokens (limits output length).
- Example request using curl:
curl https://inference.example.com/v1/predict -H "Authorization: Bearer <ACCESS_TOKEN>" -H "Content-Type: application/json" -d '{ "model": "example-llm-v2", "input": "What is the capital of France?", "temperature": 0.7, "max_tokens": 50 }' - The endpoint processes the request and invokes the model only when needed.
4. On-Demand Compute Provisioning
- The cloud platform automatically allocates compute resources just-in-time to process each inference request.
- It can scale up to handle spikes in traffic and scale down (even to zero) during idle periods, eliminating costs for unused resources.
5. Model Execution and Response
- The inference engine loads the model and executes the prediction code.
- A structured response (typically JSON) is returned, containing the model's output, such as a prediction, classification, or generated content.
6. Post-Processing and Output
- If needed, additional processing (like formatting, logging, or emitting downstream events) can be triggered automatically through integrated workflows with services like AWS Lambda, EventBridge, or similar.
- Results are sent back to the client or integrated into business workflows in real-time.
Real-World Use Cases of Serverless Inferencing
1. Chatbots & Virtual Assistants
- NLP models deployed serverlessly handle user queries on-demand.
- Example: Customer support bots powered by BERT or GPT models.
2. Recommendation Engines
- Retail and streaming platforms personalize user experience.
- Example: Netflix-like recommendations triggered per user session.
3. Computer Vision Applications
- On-demand image recognition, defect detection, facial recognition.
- Example: A factory runs quality checks with ML models triggered by camera input.
4. IoT and Edge Devices
- Edge devices trigger cloud-based serverless functions for low-latency predictions.
- Example: Smart home devices that call serverless APIs for decision-making.
5. Healthcare Applications
- Medical imaging models (X-ray or MRI scans) deployed via serverless functions.
- Serverless ensures elastic scaling for hospitals with unpredictable patient loads.

Top 10 Platforms for Serverless Inferencing
Deploying AI models serverlessly is no longer just a cloud-native experiment — it's becoming a standard practice across enterprises, startups, and research labs. Below, we explore the top 10 serverless inference platforms, analyzing their strengths, weaknesses, and ideal use cases.
1. Cyfuture AI (Leader in Enterprise-Ready Serverless Inference)
Cyfuture AI is quickly emerging as a leader in enterprise grade serverless inference, designed for organizations that need scalability, compliance, and performance. Unlike hyperscalers, which often offer one size fits all services, Cyfuture AI focuses on tailored deployments for industries such as healthcare, BFSI, retail, and IoT. By leveraging GPU as a Service, Cyfuture AI delivers next generation AI acceleration powered by the latest H100 Cloud GPUs for large scale AI and deep learning workloads, and NVIDIA L40S GPUs for generative AI, visualization, and inference at scale.
Key Features:
- GPU-powered serverless functions for deep learning workloads (transformers, vision models).
- Hybrid edge + cloud deployments for latency-sensitive AI.
- Cold start optimization with persistent caching & model warm-up strategies.
- Enterprise-grade compliance (HIPAA, GDPR, BFSI).
- Transparent pricing model → predictable costs without surprise billing.
Best For:
- Enterprises needing scalable AI inference with compliance requirements.
- Businesses exploring hybrid AI deployments across edge + cloud.
- Organizations looking for personalized AI support, not just self-service tools.
2. AWS Lambda + SageMaker
AWS pioneered the serverless revolution, and its integration of Lambda with SageMaker makes it a natural choice for inference. Developers can run lightweight functions on Lambda while delegating heavy inference tasks to SageMaker endpoints.
Key Features:
- Supports TensorFlow, PyTorch, Hugging Face, and custom models.
- Provisioned concurrency → reduces cold start latency.
- Tight integration with AWS ecosystem (S3, DynamoDB, API Gateway).
Best For:
- Businesses already invested in the AWS cloud stack.
- Developers needing instant scale-up for production AI workloads.
3. Google Cloud Functions + Vertex AI
Google's AI-first approach makes it a strong contender. Vertex AI integrates seamlessly with Cloud Functions, allowing developers to build pipelines from data ingestion to inference.
Key Features:
- Pre-built models + AutoML for quick deployment.
- Native support for TensorFlow (Google's flagship framework).
- TPU acceleration available for large-scale inference.
Best For:
- Research institutions & startups using TensorFlow.
- AI teams needing end-to-end ML pipelines (train → serve).
4. Microsoft Azure Functions + Cognitive Services
Azure provides ready-to-use AI APIs (vision, NLP, speech) that can be invoked through serverless functions. Its enterprise-friendly nature makes it popular among corporations already on Microsoft infrastructure.
Key Features:
- Pre-trained cognitive APIs for NLP, vision, speech.
- Durable Functions for long-running inference workflows.
- Integration with Power BI and Dynamics 365.
Best For:
- Enterprises in finance, government, or regulated industries.
- Organizations already using Microsoft tools and cloud services.
5. IBM Cloud Functions + Watson AI
IBM is known for its Watson AI, and pairing it with Cloud Functions (OpenWhisk-based) makes it a strong solution for enterprises needing legacy system integration with modern AI.
Key Features:
- Watson NLP, vision, and speech APIs.
- Based on Apache OpenWhisk (open-source serverless engine).
- Strong security and compliance orientation.
Best For:
- Enterprises with legacy infrastructure needing gradual AI adoption.
- Industries requiring trust, governance, and compliance.
6. Oracle Cloud Functions + AI Services
Oracle's serverless platform is powered by the Fn Project (open-source). With a strong presence in enterprise databases, Oracle enables AI inference close to enterprise data warehouses.
Key Features:
- Fn Project allows on-prem + cloud deployments.
- AI APIs for vision, language, and anomaly detection.
- Tight coupling with Oracle Autonomous Database.
Best For:
- Enterprises with heavy Oracle database reliance.
- BFSI & telecom companies needing data-local inference.
7. Alibaba Cloud Function Compute + PAI
Alibaba Cloud dominates the Asia-Pacific market with its Function Compute service and Platform for AI (PAI). It's widely used for e-commerce and fintech AI workloads.
Key Features:
- Native integration with PaddlePaddle (China's leading ML framework).
- Pre-built AI APIs for NLP, vision, and personalization.
- Scalable serverless backbone supporting millions of transactions/sec.
Best For:
- Businesses operating in China and APAC markets.
- E-commerce and fintech AI workloads.
8. Tencent Cloud Serverless + AI APIs
Tencent Cloud has a strong focus on gaming, entertainment, and social media AI. Its serverless + AI APIs are optimized for real-time workloads like speech recognition and content moderation.
Key Features:
- Serverless integration with WeChat ecosystem.
- APIs for speech, translation, and content moderation.
- Strong latency performance for gaming and media apps.
Best For:
- Gaming, entertainment, and social platforms.
- Businesses targeting China's consumer market.
9. Baidu Cloud + PaddlePaddle
Baidu's PaddlePaddle framework is one of China's most popular ML libraries. Combined with Baidu Cloud Functions, it powers AI for autonomous driving (Apollo) and voice AI.
Key Features:
- Pre-trained models for vision, NLP, and speech.
- Optimized for autonomous driving and voice assistants.
- Large Chinese-language AI ecosystem.
Best For:
- AI teams working in computer vision and NLP.
- Autonomous vehicle & mobility industries.
10. Open-Source Serverless Frameworks (Knative, OpenFaaS, Kubeless)
For organizations seeking vendor neutrality, open-source frameworks provide the building blocks of serverless inference on any cloud or on-prem environment.
Key Features:
- Knative → Kubernetes-native serverless.
- OpenFaaS → Function-as-a-Service with Docker.
- Kubeless → Simple, Kubernetes-native functions.
Best For:
- DevOps-heavy teams with Kubernetes experience.
- Enterprises avoiding vendor lock-in.
Comparison Table: Serverless Inference Platforms
| Platform | Strengths | Weaknesses | Best Suited For |
|---|---|---|---|
| Cyfuture AI | GPU-powered, hybrid edge-cloud, compliance | Newer vs hyperscalers | Enterprises, BFSI, healthcare |
| AWS Lambda | Mature ecosystem, SageMaker integration | Cold starts, AWS lock-in | Startups, enterprise AI apps |
| Google Cloud | TensorFlow & Vertex AI | Cost management complex | Research, ML pipelines |
| Azure | Enterprise tools, pre-trained APIs | Can be pricier | Government, regulated industries |
| IBM Watson | Trust & compliance | Less flexible | Legacy enterprises |
| Oracle Fn | DB integration | Limited AI ecosystem | BFSI, telco |
| Alibaba | PaddlePaddle, e-commerce | Regional lock-in | APAC companies |
| Tencent | Gaming, media AI | Niche use cases | Gaming & social |
| Baidu | Autonomous driving AI | China-centric | Automotive, NLP |
| Open-source | Vendor neutrality | Requires heavy DevOps | Enterprises avoiding lock-in |
Best Practices for AI Serverless Inference
- Optimize Models → Use smaller, faster models (quantized/distilled).
- Reduce Cold Starts → Keep functions warm, pre-load models.
- Leverage GPUs → Choose GPU-backed serverless for heavy workloads.
- Monitor & Optimize Costs → Track metrics with AWS CloudWatch, GCP Monitoring.
- Hybrid Deployments → Offload frequent workloads to containers, spiky workloads to serverless.

Read More: https://cyfuture.ai/blog/serverless-inferencing
The Future of Serverless Inferencing in AI
Serverless inferencing has already proven to be a game-changer by making AI deployments more scalable, affordable, and developer-friendly. However, this is just the beginning. Over the next 5–10 years, the convergence of cloud, edge, and AI innovations will completely reshape how inference workloads are deployed.
Here are eight key trends that will define the future of serverless inferencing:
1. Edge + Cloud Hybrid Inference Becomes the Norm
Currently, most serverless inference is cloud-based, but many industries (healthcare, automotive, manufacturing) require ultra-low latency and data privacy that the cloud alone cannot deliver.
- Hybrid architecture will emerge: Lightweight models run on edge devices, while complex tasks are offloaded to serverless cloud functions.
- Example: An autonomous vehicle uses edge inference for object detection but calls the cloud serverless function for advanced decision-making.
- Impact: Enterprises get the best of both worlds → low latency + infinite scalability.
2. Serverless GPUs and TPUs Become Mainstream
Today, serverless functions are mostly CPU-bound, limiting large model performance. However, cloud providers (and challengers like Cyfuture AI) are rolling out GPU-backed serverless environments.
- Expect widespread support for GPU/TPU acceleration in serverless platforms.
- This will make it possible to serve large deep learning models (transformers, diffusion models) serverlessly.
- Impact: Complex AI models (NLP, vision, generative AI) become accessible to startups and enterprises alike.
3. Hugging Face-Style Model Marketplaces Go Serverless
Model hubs like Hugging Face and TensorFlow Hub are already popular for pre-trained AI models. The future? One-click serverless deployment directly from these marketplaces.
- Example: Deploy a BERT model or Stable Diffusion with a single command, automatically hosted on serverless infrastructure.
- Providers like Cyfuture AI can integrate model hubs into their serverless platforms.
- Impact: AI democratized → developers and even non-technical teams can serve models instantly.
4. Specialized Serverless Platforms for Industries
Generic serverless platforms are great, but industries have unique compliance, performance, and security needs.
- Healthcare → HIPAA-compliant serverless AI for medical imaging.
- Finance → Low-latency, audited inference for fraud detection.
- Retail → Personalized recommendations at scale.
Cyfuture AI could lead here by offering verticalized serverless AI solutions, tailored to industry regulations and workflows.
5. Multi-Cloud and Interoperability Standards
Vendor lock-in is a growing concern with AWS, GCP, and Azure. The future will see multi-cloud serverless orchestration, where inference workloads run seamlessly across providers.
- Open standards (like Knative) will make it easier to move inference functions between providers.
- Federated serverless AI could enable workloads to run where latency, compliance, or cost is optimal.
- Impact: Enterprises gain flexibility and resilience.
6. Cost-Aware and Self-Optimizing Serverless AI
Currently, serverless costs can spike unexpectedly. In the future:
- AI-driven orchestration will predict workloads and optimize execution.
- Models will auto-adjust batch sizes, concurrency, or placement (edge vs cloud).
- Cost-aware inference will dynamically switch between CPU/GPU modes depending on load.
- Impact: Enterprises maximize performance while keeping costs predictable.
7. Quantum + Serverless AI Integration
While still experimental, quantum computing is advancing. Imagine a future where quantum-powered functions can be triggered via serverless APIs for tasks like:
- Optimization problems in logistics.
- Quantum-accelerated training for ML models.
- Faster simulations in scientific research.
- AutoML + serverless orchestration will create pipelines where models train, optimize, and deploy without human intervention.
- A new AI model → automatically packaged → deployed serverlessly → scaled based on real-time demand.
- Impact: Drastically reduces time-to-market for AI solutions.
Serverless quantum inference could emerge as a hybrid offering, with AI pre/post-processing happening on classical functions.
8. Autonomous AI Deployment Pipelines
Currently, deploying models requires ML engineers + DevOps. But in the near future:
Summary of Future Predictions
| Future Trend | Impact on AI Serverless Inference |
|---|---|
| Edge + Cloud Hybrid | Low latency + scalability |
| GPU/TPU Serverless | Larger deep learning models feasible |
| Model Marketplaces | One-click deployment democratizes AI |
| Industry-Specific Platforms | Compliance-ready, tailored AI |
| Multi-Cloud Standards | Avoid vendor lock-in |
| Cost-Aware Inference | Predictable, optimized spending |
| Quantum Integration | Future-proof AI workloads |
| Autonomous Pipelines | AI deployment without DevOps bottlenecks |
Interesting Blog: https://cyfuture.ai/blog/serverless-ai-inference-h100-l40s-gpu
Conclusion
Serverless inferencing is redefining AI deployment. From startups to Fortune 500s, it offers cost efficiency, scalability, and simplicity — all without the burden of managing infrastructure.
While hyperscalers (AWS, GCP, Azure) provide strong ecosystems, Cyfuture AI leads with enterprise-ready, GPU-powered, and compliance-focused serverless inference solutions.
If you're planning to scale AI securely and cost-effectively, Cyfuture AI should be your platform of choice.
FAQs:
1. What is serverless inferencing?
Serverless inferencing is the deployment of AI/ML models on serverless platforms without managing infrastructure. Models run only when triggered and scale automatically.
2. Is serverless inferencing cost-effective?
Yes. Serverless inferencing is cost-effective for spiky or unpredictable workloads since you only pay when functions run, eliminating idle server costs.
3. Can large AI models run on serverless platforms?
Yes, but large models may require optimization (quantization, pruning) or GPU-backed serverless platforms like Cyfuture AI, AWS, or GCP.
4. Which platforms support serverless inference?
Top platforms include Cyfuture AI, AWS Lambda + SageMaker, Google Cloud + Vertex AI, Azure Functions, IBM Watson, Oracle AI, Alibaba Cloud, Tencent Cloud, Baidu PaddlePaddle, and open-source frameworks like Knative and OpenFaaS.
5. What is the future of serverless inference?
Future trends include edge-cloud hybrid inference, GPU/TPU-backed functions, model marketplaces with one-click deployment, industry-specific platforms, cost-aware optimization, and even quantum + serverless AI integration.