




































































Artificial Intelligence infrastructure is entering a completely new era in 2026. And here’s the interesting part: traditional GPU clusters are no longer enough for trillion-parameter AI models, autonomous agents, and real-time reasoning systems.
That’s where the NVIDIA GB300 Superchip enters the picture.
Built on the next-generation Blackwell Ultra architecture, the GB300 is not just another GPU server. It is a rack-scale AI supercomputing platform engineered for exascale AI factories, ultra-large language models, and enterprise-grade AI reasoning workloads.
For enterprises, developers, AI researchers, and tech leaders, understanding the GB300 is becoming essential because AI infrastructure decisions made today will directly impact scalability, cost-efficiency, and competitive advantage tomorrow.
And that’s exactly what this blog explores.

Definition Box
|
|
The AI Factory Era Has Arrived—and It's Powered by GB300
Here's the thing: if you're a tech leader, developer, or enterprise strategist in 2026, you've already heard the buzz. But let's cut through the noise.
The NVIDIA GB300 Grace Blackwell Ultra Superchip isn't just another chip announcement. It's the foundation of what NVIDIA calls the "AI Factory"—and it's delivering performance numbers that sound almost too good to be true.
Want to know what makes it so revolutionary? Keep reading.
Why the NVIDIA GB300 Matters in 2026
AI models are becoming exponentially larger.
According to industry estimates, frontier AI models are expected to exceed 100 trillion parameters in the coming years. Traditional enterprise GPU servers often struggle with memory bottlenecks, network latency, and scaling inefficiencies.
Now here’s the game-changer:
The NVIDIA GB300 NVL72 architecture transforms an entire rack into what behaves like a “single giant GPU.”
That means:
- Faster distributed training
- Lower interconnect latency
- Higher inference throughput
- Reduced networking bottlenecks
- Better AI reasoning performance
And the numbers are impressive.
The GB300 platform delivers:
- Up to 15 PFLOPS Dense FP4 compute per GPU
- 288GB HBM3e memory per GPU
- A unified 72-GPU NVLink domain
- Up to 1.5× AI performance improvement over earlier GB200 systems
For AI factories and hyperscale deployments, this is a monumental leap.
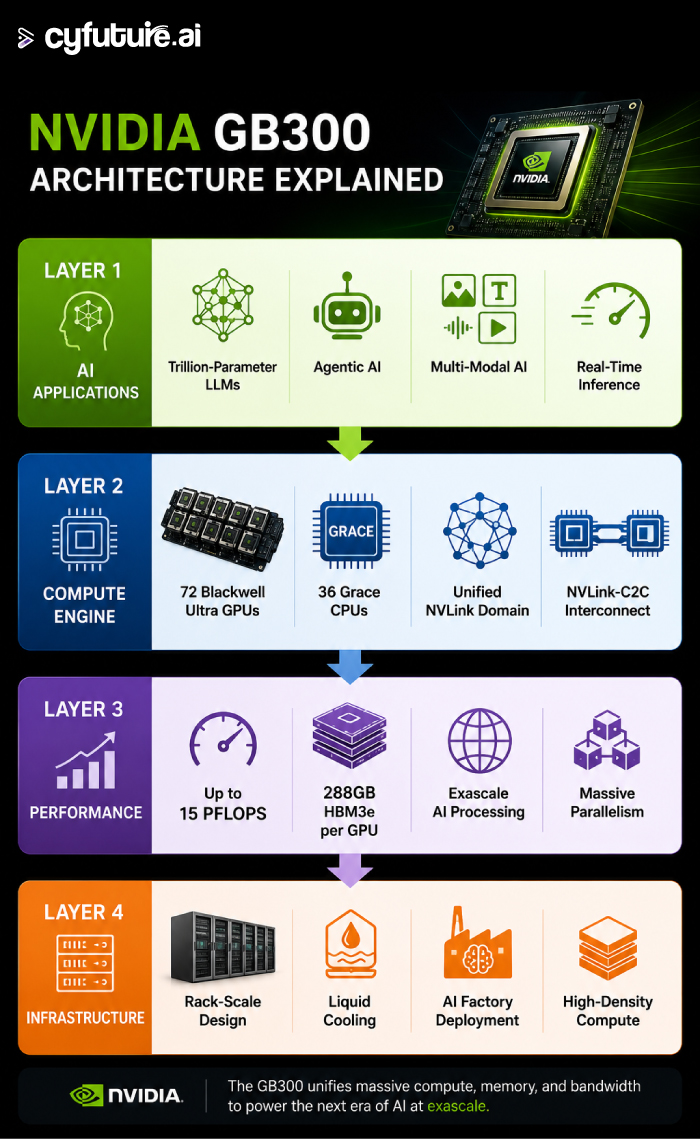
Core Architecture: What Makes GB300 Different?
The GB300 elevates the standard set by the previous GB200 platform by packing more memory and compute into a tightly coupled system.
The Compute Core Breakdown
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
But wait—there's more.
The GB300 uses second-generation NVLink-C2C interconnect, allowing the GPU and CPU to share a coherent, unified memory pool for blazing-fast data access. This means no more bottlenecks when moving data between CPU and GPU—critical for AI reasoning tasks that require massive context lengths.
Performance Numbers That Will Blow Your Mind
Let's talk hard numbers, because this is where GB300 separates itself from the pack.
AI Performance Metrics (Per NVL72 Rack)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Here's the kicker: 1.44 exaFLOPS of FP4 Tensor Core performance per VM—creating a massive, unified memory space essential for reasoning models, agentic AI systems, and complex multimodal generative AI.
Form Factors: From Desktop to Data Center
The GB300 powers everything from personal desk-side supercomputers to massive multi-rack data center clusters.
Two Primary Deployments
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The NVIDIA DGX Station is the ultimate deskside AI supercomputer for building and running AI locally—capable of developing and fine-tuning models up to 1 trillion parameters.
NVIDIA GB300 vs NVIDIA B200
Many enterprises are currently comparing the NVIDIA B200 with the GB300.
Here’s a simplified technical comparison:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
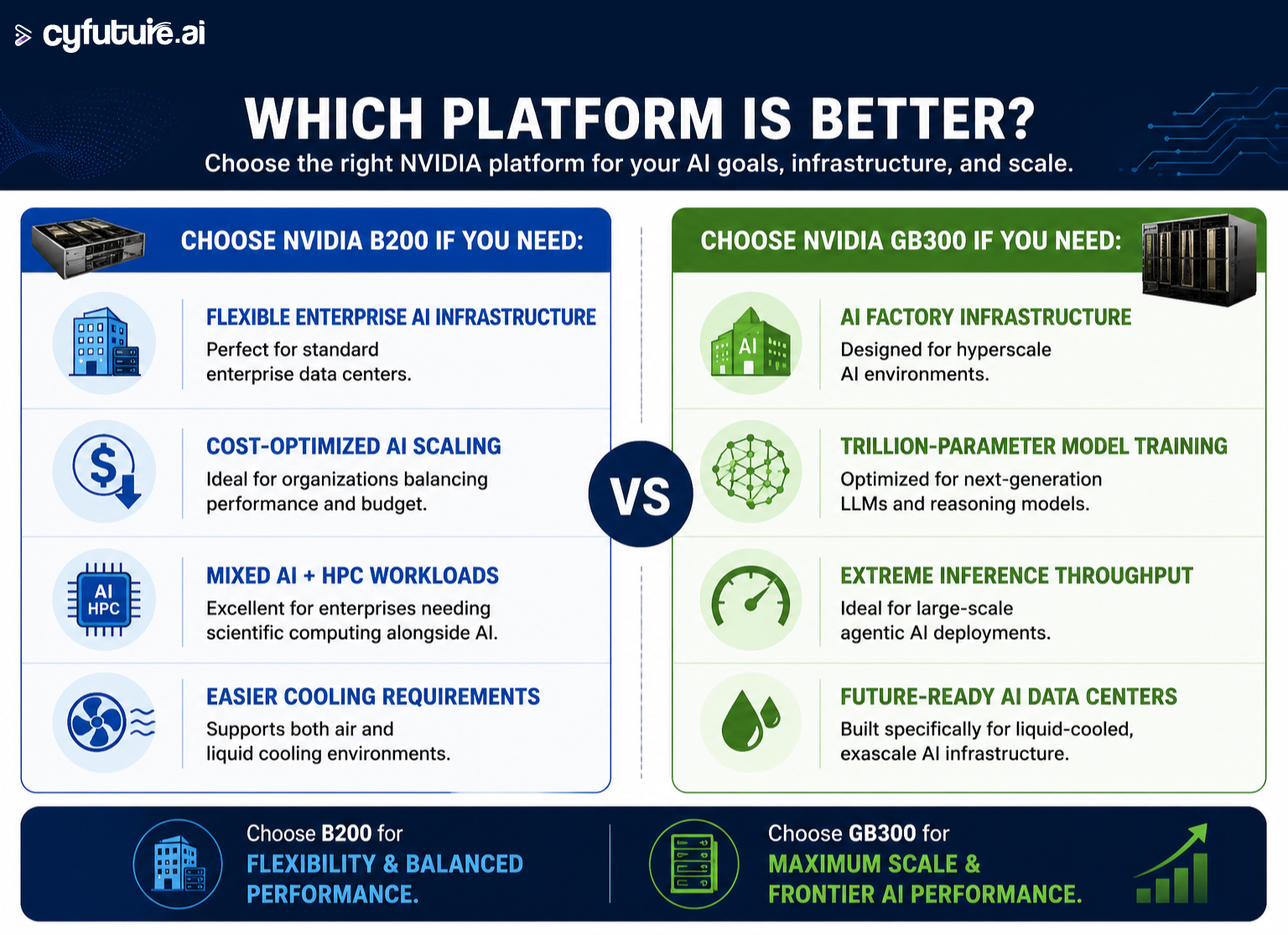
Why GB300 Matters for Your Organization
Let's be honest: AI infrastructure decisions are expensive. But here's why GB300 changes the calculus.
Key Advantages
- 50% more memory than the base B200 setup (576 GB HBM3e vs. previous generations)
- 50× increase in overall AI factory output compared to Hopper platforms
- 30× faster real-time LLM inference (building on GB200's breakthrough)
- Fully liquid-cooled architecture for maximum efficiency at scale
How Cyfuture AI Supports Next-Generation AI Infrastructure
At Cyfuture AI, enterprises gain access to scalable AI infrastructure engineered for modern AI workloads.
Cyfuture AI offers:
- High-performance GPU cloud infrastructure
- Enterprise-grade AI deployment environments
- Scalable AI compute solutions
- Low-latency AI hosting capabilities
- Secure and compliant AI infrastructure
Additionally:
- Cyfuture AI delivers enterprise-ready cloud solutions with robust uptime reliability.
- The platform supports scalable AI deployment models for startups, enterprises, and research organizations alike.
As AI adoption accelerates in 2026, infrastructure readiness is becoming a strategic differentiator.
And that’s exactly where modern GPU infrastructure matters most.
Why Tech Leaders Choose Cyfuture AI
- GPU as a Service: Deploy powerful cloud GPU infrastructure instantly, without the cost or complexity of owning hardware
- On-demand access to enterprise-grade NVIDIA GPUs built for AI model training, LLMs, and HPC
- Scalable infrastructure: From single on-demand GPU instances to 64-GPU InfiniBand clusters—designed for India's most demanding AI workloads
- High-speed NVMe storage + low-latency networking with secure, enterprise-grade AI infrastructure

The Bottom Line
The NVIDIA GB300 isn't just an incremental upgrade—it's the foundation for the next decade of AI reasoning, agentic systems, and enterprise AI at scale.
Whether you're a hyperscaler deploying massive clusters or a developer fine-tuning models locally, GB300 delivers the performance, memory, and efficiency you need to stay competitive in 2026 and beyond.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.