




































































Introduction: Why Every AI Company Is Talking About Vera Rubin
If you work anywhere near AI, cloud computing, or data centers, you have almost certainly heard the name 'Vera Rubin' recently. But who — or what — is Vera Rubin, and why is the entire technology industry treating it like the most important chip announcement in years?
This blog covers everything from the very beginning: the moment Jensen Huang first whispered the name 'Rubin' to the world at Computex 2024, through to June 2026, when Vera Rubin chips are rolling off production lines and heading to hyperscalers around the globe. Whether you are an AI researcher, a data center architect, a tech investor, or simply someone trying to understand what all the fuss is about, this guide will break it down in plain language.
|
|
Section 1: The Origin Story — From a Name to a Revolution
Who Was Vera Rubin? The Scientist Behind the Name
Before we talk chips, let us talk about the person. NVIDIA names its GPU architectures after great scientists, and 'Vera Rubin' is no exception.
Vera Rubin (1928–2016) was an American astronomer whose work fundamentally changed how we understand the universe. She spent decades studying how galaxies rotate and discovered something extraordinary: the outer edges of galaxies were spinning far too fast to be explained by the visible matter alone. Her research provided some of the strongest evidence for the existence of dark matter — the invisible substance that makes up roughly 27% of the universe.
Rubin was known not just for her brilliance but for her persistence in a field dominated by men. She was the first woman permitted to use the Palomar Observatory. She was a tireless advocate for women in science. And she changed cosmology forever.
NVIDIA chose her name for their most powerful AI chip because, like Rubin's discoveries, this chip is designed to illuminate what was previously invisible — unlocking AI capabilities that simply were not possible before.
May 2024: Jensen Huang First Unveils 'Rubin' at Computex Taipei
The first time the world heard the name 'Rubin' in a GPU context was at Computex 2024 in Taipei, Taiwan — one of the world's largest tech trade shows. NVIDIA CEO Jensen Huang dropped a bombshell during his keynote address.
While the Blackwell architecture had not even finished ramping up production, Huang told the audience that NVIDIA already had the next generation planned. He called it 'Rubin.' It would feature the new Rubin GPU paired with a new CPU called Vera. It would arrive in 2026. And it would make Blackwell look modest by comparison.
The reaction was immediate. Stock analysts recalculated their price targets. Data center operators began asking whether their current infrastructure plans still made sense. The AI industry — already moving at breakneck speed — realised it was about to accelerate even further.
|
|
March 2025: GTC 2025 — Full Architecture Details Revealed
At NVIDIA's annual GPU Technology Conference (GTC) in San Jose, California in March 2025, Jensen Huang returned to the Vera Rubin story with much greater detail.
This was not just a teaser anymore. NVIDIA published the roadmap, showed the architecture, and confirmed the specifications. Here is what the audience learned:
- The Rubin GPU would be built on TSMC's 3-nanometre process — the most advanced chip manufacturing technology available.
- It would be a dual-die design: two separate silicon dies packaged together as one GPU, totalling 336 billion transistors.
- Each Rubin GPU would deliver 50 petaFLOPs of NVFP4 inference performance — 5 times more than Blackwell.
- The accompanying Vera CPU would feature 88 custom ARM 'Olympus' cores.
- The flagship system — the Vera Rubin NVL72 — would pack 72 Rubin GPUs and 36 Vera CPUs into a single liquid-cooled rack.
- Rubin Ultra would follow in the second half of 2027, and Feynman GPUs in 2028.
GTC 2025 also confirmed something that sent chills through the data center industry: the Vera Rubin NVL72 would be 100% liquid cooled. Air cooling, which had served the data center world for decades, was officially no longer sufficient for next-generation AI workloads.
January 2026: CES 2026 — Jensen Huang Announces Full Production
Fast forward to the Consumer Electronics Show (CES) in Las Vegas, January 2026. Jensen Huang took the stage and delivered the announcement the industry had been waiting for: Vera Rubin is in full production.
This was not a lab demo or a prototype. NVIDIA had received all six chips back from TSMC's foundry, partners were already running workloads on them, and the company was ready to begin ramping shipments for the second half of 2026.
The CES announcement also gave us the first confirmed customer list: Amazon Web Services (AWS), Google Cloud, Microsoft Azure, Oracle Cloud Infrastructure (OCI), CoreWeave, Lambda, Nebius, and Nscale were all named as launch partners.
In his speech, Huang also confirmed that the Vera Rubin NVL72 could reduce inference token costs by 10 times compared to Blackwell — a figure that immediately changed the economics of running large AI models.
March 2026: GTC 2026 — The Full Platform Revealed, Now with 7 Chips
At GTC 2026, NVIDIA went even further. The Vera Rubin platform was expanded to seven chips (up from six) with the surprise inclusion of the Groq 3 LPU (Language Processing Unit) — the result of NVIDIA's reported $20 billion acqui-hire of Groq.
NVIDIA also unveiled the Vera Rubin POD: a 40-rack AI supercomputer comprising 1,152 Rubin GPUs, delivering 60 exaFLOPs of compute power and 10 petabytes per second of total memory bandwidth. This is not a system for one company to buy. It is what AI factories look like now.

Section 2: What Is Inside the Vera Rubin? A Plain-Language Technical Guide
You do not need a computer science degree to understand what makes Vera Rubin special. Let us break it down, piece by piece.
The Rubin GPU (R100): The Powerhouse
Think of the GPU as the engine. The Rubin GPU — officially called the R100 — is the core of the entire Vera Rubin platform. Here is what makes it remarkable:
- 336 billion transistors: To put this in perspective, a single human hair is about 70,000 nanometres wide. A transistor on this chip is about 3 nanometres — roughly 23,000 times smaller.
- 288 GB of HBM4 memory per GPU: HBM4 is the newest, fastest type of memory available. Each Rubin GPU carries 288 gigabytes of it at up to 22 terabytes per second of bandwidth — nearly three times faster than the Blackwell generation.
- 50 petaFLOPs of AI inference: One petaFLOP equals one quadrillion mathematical operations per second. The R100 does 50 of these every second, specifically for AI inference workloads.
- 35 petaFLOPs of AI training: Training AI models is computationally different from running them. Rubin handles both at record speeds.
The Vera CPU: The Brain That Runs the Engine
Every GPU needs a CPU to tell it what to do. NVIDIA designed the Vera CPU from scratch specifically to keep pace with the Rubin GPU. Previous generations of NVIDIA's Grace CPU are already faster than anything from Intel or AMD for AI workloads — and Vera is twice as fast as Grace.
- 88 custom ARM 'Olympus' cores
- NVIDIA's new 'Spatial Multi-Threading' technology effectively doubles the usable thread count to 176
- 227 billion transistors
- Up to 1.5 TB of LPDDR5X memory with 1.2 TB/s bandwidth
HBM4 Memory: Why It Changes Everything
|
|
NVLink 6: The Nervous System Connecting Everything
When 72 GPUs need to work together as one system, they need a way to share information at extraordinary speed. That is what NVLink 6 does. It is NVIDIA's proprietary high-speed interconnect, and in the Vera Rubin NVL72, it provides 260 terabytes per second of total fabric bandwidth — double the 130 TB/s of NVLink 5 in Blackwell.
To put that in perspective: The entire global internet transfers approximately 0.1 exabytes of data per day. The NVLink 6 fabric in a single Vera Rubin rack can move 260 terabytes of data every second.
The Complete Vera Rubin Platform: Seven Co-Designed Chips
What makes Vera Rubin genuinely different from previous GPU generations is that it is not just a new GPU. It is an entire co-designed platform where every component was built to work together:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The Vera Rubin NVL72 Rack: One Rack to Rule Them All
The NVL72 is NVIDIA's flagship product — a single server rack that combines 72 Rubin GPUs and 36 Vera CPUs. Think of it as a supercomputer in a cabinet.
- 3.6 ExaFLOPs of NVFP4 inference compute per rack
- 2.5 ExaFLOPs of training compute per rack
- 20.7 TB of HBM4 memory, plus 54 TB of LPDDR5X
- 1.6 petabytes per second of total memory bandwidth
- 100% liquid cooled — no fans, no air cooling
- Cable-free modular tray design — assembly time reduced from 90+ minutes to approximately 5 minutes
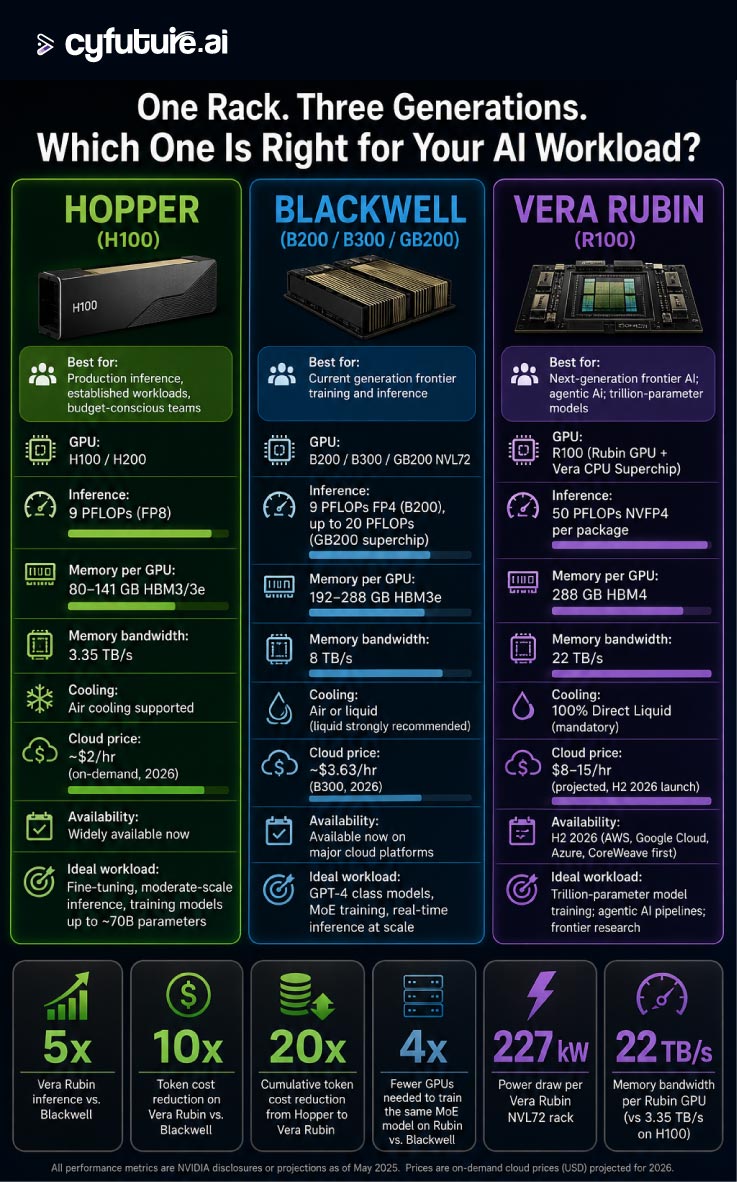
Section 3: How Does Vera Rubin Compare to Blackwell and Hopper?
One of the most common questions about Vera Rubin is: how much better is it, really? Here is a direct comparison across the three most recent NVIDIA GPU generations:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
What Do These Numbers Mean in Practice?
Raw numbers are one thing. Real-world impact is another. Here is what the Vera Rubin performance leap actually means for AI teams:
- Training a large language model that took 100 GPU-days on Hopper would take roughly 7 GPU-days on Vera Rubin — using one-quarter the number of GPUs.
- Running Mixture-of-Experts (MoE) models — the architecture behind systems like GPT-4 and Gemini — costs one-tenth as much per token on Rubin compared to Blackwell.
- Trillion-parameter models that previously required hundreds of GPUs working in concert can increasingly be served from the memory of a single Vera Rubin rack.
- The cumulative token cost reduction from Hopper to Rubin is approximately 20 times — meaning AI is becoming roughly 20x more affordable per query in three years.
Section 4: Why Vera Rubin Is 100% Liquid Cooled — And What That Means
The Heat Problem: Why Air Cooling Is No Longer Enough
Here is a fact that surprises most people outside the data center world: the biggest challenge in AI computing is not building faster chips. It is getting rid of the heat those chips produce.
A single Vera Rubin NVL72 rack draws up to 227 kilowatts of power. That is roughly equivalent to the electricity consumption of 75 average Indian households — all concentrated into a cabinet roughly 2 metres tall. Traditional air cooling, which uses fans to blow cool air over components, simply cannot remove heat at that density fast enough.
This is why NVIDIA made a decision that will reshape data center infrastructure globally: Vera Rubin is liquid cooled only. There is no air-cooled version.
How Liquid Cooling Works: The Simple Explanation
Liquid cooling works by flowing water (or a water-glycol mixture) through metal plates called 'cold plates' that sit directly on top of the chips. Because water carries heat approximately 3,500 times more efficiently than air, it can remove enormous amounts of heat from a tiny surface area.
In the Vera Rubin NVL72, this is called Direct-to-Chip cooling. Cold plates press against every GPU and CPU, extracting heat at the source. The warm water then flows to a cooling distribution unit (CDU), where it releases its heat before recirculating.
The result: a 227 kW rack stays operational, reliable, and thermally stable — something physically impossible with air cooling.
The Rack Power Density Revolution: A Timeline
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Why This Matters for Data Centers Everywhere
The shift to liquid-only cooling is not a minor technical upgrade. It represents a fundamental change in what a data center needs to look like. Facilities built around air cooling — raised floors, hot/cold aisle containment, massive CRAC units — are not designed to support 227 kW racks.
This creates a significant infrastructure challenge for any organisation planning to run next-generation AI workloads. And it is why data centers built specifically with liquid cooling infrastructure from the ground up — like Cyfuture Cloud's 10 MW AI data center — are so strategically important.

Section 5: What Can You Actually Do with Vera Rubin? Real-World Use Cases
The performance specs are impressive. But what does Vera Rubin actually enable that was not possible before? Here are the most impactful use cases:
1. Training Frontier AI Models
The biggest AI models in the world — the ones that power ChatGPT, Gemini, Claude, and their successors — require months of computation on thousands of GPUs. Vera Rubin reduces that compute requirement by 4x. What took 1,000 Blackwell GPUs can now be done with 250 Rubin GPUs — dramatically cutting cost and time-to-production for AI labs.
2. Real-Time AI Inference at Scale
Inference is what happens when you type a question into an AI chatbot and it responds. Each response requires thousands of GPU operations. Vera Rubin's 10x reduction in cost per token means AI companies can serve dramatically more users without proportionally increasing their infrastructure spend. This is what makes large-scale AI applications commercially viable.
3. Agentic AI: The Next Frontier
Agentic AI refers to AI systems that do not just answer questions — they take sequences of actions autonomously. Think of an AI agent that books your travel, manages your calendar, writes code, and coordinates with other AI agents to complete complex tasks. These workflows require persistent context (large memory), fast inference, and low latency — all areas where Vera Rubin excels.
NVIDIA explicitly designed the Vera Rubin platform for agentic AI, with the Groq 3 LPU in the LPX rack configuration specifically targeting low-latency decode for trillion-parameter model workloads.
4. Scientific Research and Drug Discovery
Protein folding, climate modelling, materials science, particle physics — these fields are being transformed by AI. The FP64 (double precision) compute in Vera Rubin makes it suitable not just for AI inference but for traditional high-performance computing (HPC) workloads that require extreme numerical precision.
5. Autonomous Vehicles and Robotics
Training AI systems for autonomous driving requires processing billions of hours of video data. Vera Rubin's memory capacity and bandwidth make it ideal for these training workloads. As physical AI — robotics — becomes the next major frontier, the computational demands will be even greater.
6. Healthcare and Medical Imaging
Large-scale medical imaging analysis, genomic sequencing, drug-protein interaction modelling — these are workloads that require both the precision and the memory capacity that Vera Rubin offers. AI is accelerating drug discovery timelines from 12 years to as few as 3, and Vera Rubin is part of that infrastructure.
Section 6: NVIDIA's GPU Roadmap — Where Does Vera Rubin Fit?
Understanding Vera Rubin requires understanding the larger picture of where NVIDIA is going. The company has committed to an annual cadence of major architecture updates, which is unprecedented in chip design history.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Rubin Ultra (2027): Even More Power
Rubin Ultra, expected in the second half of 2027, will essentially double the Rubin GPU by packaging four silicon dies instead of two. This is expected to deliver approximately 100 petaFLOPs of FP4 inference per GPU package and up to 1 TB of HBM4E memory. The Rubin Ultra NVL576 rack will house 576 GPUs and consume over 600 kilowatts.
Feynman (2028): The Next Giant Leap
Named after Nobel Prize-winning physicist Richard Feynman, the 2028 generation is expected to introduce 3D stacking technology — a fundamentally different way of building chips where layers of silicon are stacked vertically. It will be paired with the Rosa CPU (named after Nobel laureate Rosalyn Sussman Yalow) and will use a custom HBM memory generation beyond HBM4. Few details are confirmed at this stage.
|
|
Section 7: Cyfuture’s 10 MW Liquid Cooled AI Data Center — Built for Vera Rubin and Beyond
The arrival of Vera Rubin is not just a chip story. It is an infrastructure story. And here is the challenge: most data centers in the world are simply not ready for it.
A Vera Rubin NVL72 rack draws 227 kW of power and requires direct liquid cooling. The average enterprise data center — even a modern one — was designed for air-cooled racks drawing 10 to 30 kW. The gap between what Vera Rubin needs and what most facilities can provide is enormous.
This is precisely why Cyfuture built its 10 MW Liquid Cooled AI Data Center — and why it is now one of the most strategically important infrastructure assets in India.
What Makes the Cyfuture 10 MW Data Center Different
Most data centers are retrofitted for liquid cooling — meaning liquid cooling is added to a facility originally designed for air. Cyfuture's facility was designed from the ground up with liquid cooling as the foundation. This means:
- Direct-to-Chip cooling infrastructure throughout the facility, not just in select zones
- Cooling Distribution Units (CDUs) capable of handling the thermal loads of current and next-generation GPU racks
- Power infrastructure designed for high-density deployments — supporting the 150 to 600+ kW rack power envelopes that Vera Rubin and Rubin Ultra demand
- Physical space and structural floor loading rated for the weight of liquid-cooled rack-scale systems (the Vera Rubin NVL72 weighs approximately 1,800 kg)
- Redundant cooling loops to ensure zero downtime even during CDU maintenance
GPU Compatibility: Present and Future
Cyfuture’s data center was built to be generation-agnostic. It is designed to support:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Why India Needs AI Infrastructure Like This
India is rapidly becoming one of the world's most significant AI markets. With a massive base of software engineers, growing investment in AI-first startups, and government initiatives like 'AI for India,' the demand for high-performance AI compute is accelerating.
Yet the vast majority of India's existing data center capacity is not equipped for next-generation AI workloads. The air-cooled colocation facilities that handle enterprise IT workloads are fundamentally unsuitable for Vera Rubin-class deployments.
Cyfuture’s 10 MW facility changes that equation. It gives Indian AI companies, research institutions, and enterprises access to the same infrastructure available to global hyperscalers — without the latency or data sovereignty complications of routing workloads to US or European facilities.
SEZ Benefits and Strategic Location
Cyfuture’s data center is located within a Special Economic Zone (SEZ), providing significant advantages for businesses operating AI workloads:
- Tax benefits and duty exemptions on hardware imports — directly reducing the cost of deploying Vera Rubin and future-generation GPUs
- Streamlined regulatory environment for technology operations
- Strong connectivity to domestic and international fiber networks
- Proximity to India's major technology hubs, reducing latency for domestic users

Section 8: Frequently Asked Questions About NVIDIA Vera Rubin
These are the questions that appear most frequently when people search for information about Vera Rubin — directly addressing the topics surfaced in Google's AI Overview for this subject.
Q: When will NVIDIA Vera Rubin be available?
Vera Rubin (R100) GPUs are in full production as of early 2026. Partner availability through cloud providers including AWS, Google Cloud, Microsoft Azure, CoreWeave, and others begins in the second half of 2026. Broader availability, including through specialist GPU cloud providers, is expected through 2027.
Q: How much faster is Vera Rubin than Blackwell?
At the GPU level, Rubin delivers 5x more inference performance and 3.5x more training performance than Blackwell. At the system level (rack vs. rack), the improvement is even greater: 3.6 ExaFLOPs of inference compute per Vera Rubin NVL72 rack versus approximately 1 ExaFLOP for the Blackwell NVL72. Token costs fall by 10x.
Q: Why is Vera Rubin liquid cooled only?
The Vera Rubin NVL72 rack draws up to 227 kilowatts of power. At this power density, air cooling is physically insufficient to maintain safe operating temperatures for the chips. Direct liquid cooling, where coolant flows through metal plates pressed directly onto the chips, is the only thermal solution capable of removing heat at this rate. This is an industry-wide trend — every major GPU vendor is moving to liquid cooling for next-generation products.
Q: What is the difference between Vera Rubin and Rubin Ultra?
Vera Rubin (R100), shipping in H2 2026, uses a dual-die GPU package (two silicon dies per GPU) delivering 50 PFLOPs of FP4 inference. Rubin Ultra (R300), expected in H2 2027, uses a quad-die GPU package (four silicon dies) and is expected to deliver approximately 100 PFLOPs per GPU. Rubin Ultra will also use HBM4E (an enhanced version of HBM4) and will be packaged in the Rubin Ultra NVL576 — a rack holding 576 GPU packages.
Q: What is HBM4 and why does it matter for AI?
HBM4 (High Bandwidth Memory, 4th generation) is the memory technology used in Vera Rubin. Compared to HBM3e (used in Blackwell), HBM4 doubles the interface width and delivers nearly 3x the memory bandwidth — up to 22 TB/s per GPU in Vera Rubin. For AI workloads, memory bandwidth is often the primary bottleneck: the faster memory can feed data to the GPU's compute cores, the faster the AI model runs. HBM4 essentially removes memory bandwidth as a constraint for most current AI architectures.
Q: Is Vera Rubin CUDA compatible? Do I need to rewrite my code?
No code changes are required. NVIDIA maintains backward compatibility across its GPU generations through CUDA, its parallel computing platform. Workloads running on Hopper or Blackwell will run on Vera Rubin without modification. In many cases, they will run significantly faster without any optimisation, and with targeted optimisations (such as taking advantage of NVFP4 precision and the new Groq 3 LPU for decode) performance gains can be even greater.
Q: What companies will use Vera Rubin first?
The confirmed launch cohort includes AWS, Google Cloud, Microsoft Azure, OCI, CoreWeave, Lambda, Nebius, and Nscale, with shipments starting in H2 2026. Crusoe and Together AI have also been confirmed as additional launch partners. Enterprise customers will access Vera Rubin primarily through these cloud providers initially, with dedicated infrastructure deployments (like those at Cyfuture Cloud) becoming available as supply scales through 2026 and 2027.
Q: What comes after Vera Rubin?
NVIDIA's confirmed roadmap shows Rubin Ultra arriving in H2 2027 and Feynman GPUs in 2028. Rubin Ultra doubles the compute of Vera Rubin by packing four GPU dies per package. Feynman will introduce 3D stacking technology, custom HBM memory, and will be paired with the Rosa CPU and ConnectX-10 networking. The 2029–2030 roadmap includes 'Rosa Feynman Spark' for workstation and portable formats.
Conclusion: The Vera Rubin Era Has Begun
Vera Rubin is not just a chip. It is a statement about where artificial intelligence is going.
From the moment Jensen Huang first teased 'Rubin' at Computex 2024, through the detailed architecture reveal at GTC 2025, to the full production announcement at CES 2026 and the comprehensive platform details at GTC 2026 — every milestone has confirmed the same thing: the pace of AI hardware advancement is not slowing down. It is accelerating.
For AI researchers, Vera Rubin means training frontier models faster and cheaper than ever before. For AI companies, it means serving more users at dramatically lower cost per query. For data center operators, it means that liquid cooling is no longer optional — it is the only path forward.
And for India's AI ecosystem, Cyfuture's 10 MW liquid-cooled AI data center represents exactly the kind of infrastructure that makes world-class AI development possible on home soil.
The question is not whether Vera Rubin will change AI. It already has. The question is whether your infrastructure is ready.
Author Bio:
Meghali is a tech-savvy content writer with expertise in AI, Cloud Computing, App Development, and Emerging Technologies. She excels at translating complex technical concepts into clear, engaging, and actionable content for developers, businesses, and tech enthusiasts. Meghali is passionate about helping readers stay informed and make the most of cutting-edge digital solutions.